Interacting with a Corpus of Sounds
Corpus-based concatenative synthesis (CBCS) is a recent sound synthesis method that is based on descriptor analysis of any number of existing or live-recorded sounds and synthesis by selection of sound segments from the database matching sound characteristics given by the user. While the previous phase of research focused mainly on the analysis and synthesis methods, and handling of the corpus, current research now turns more and more towards how expert musicians, designers, the general public or children can interact efficiently and creatively with a corpus of sounds. We will first look at gestural control of the navigation through the sound space, how it can be controlled by audio input to transform sound in surprising ways, or to transcribe and re-orchestrate environmental sound. Then we will consider its use for live performance, especially in an improvisation setting between an instrumental and a CBCS performer, where recording the corpus live from the instrument creates a stronger and more direct coupling between them. Finally, we will discuss sound installations that open up discovery and interaction with rich sound corpora to the general public and children.
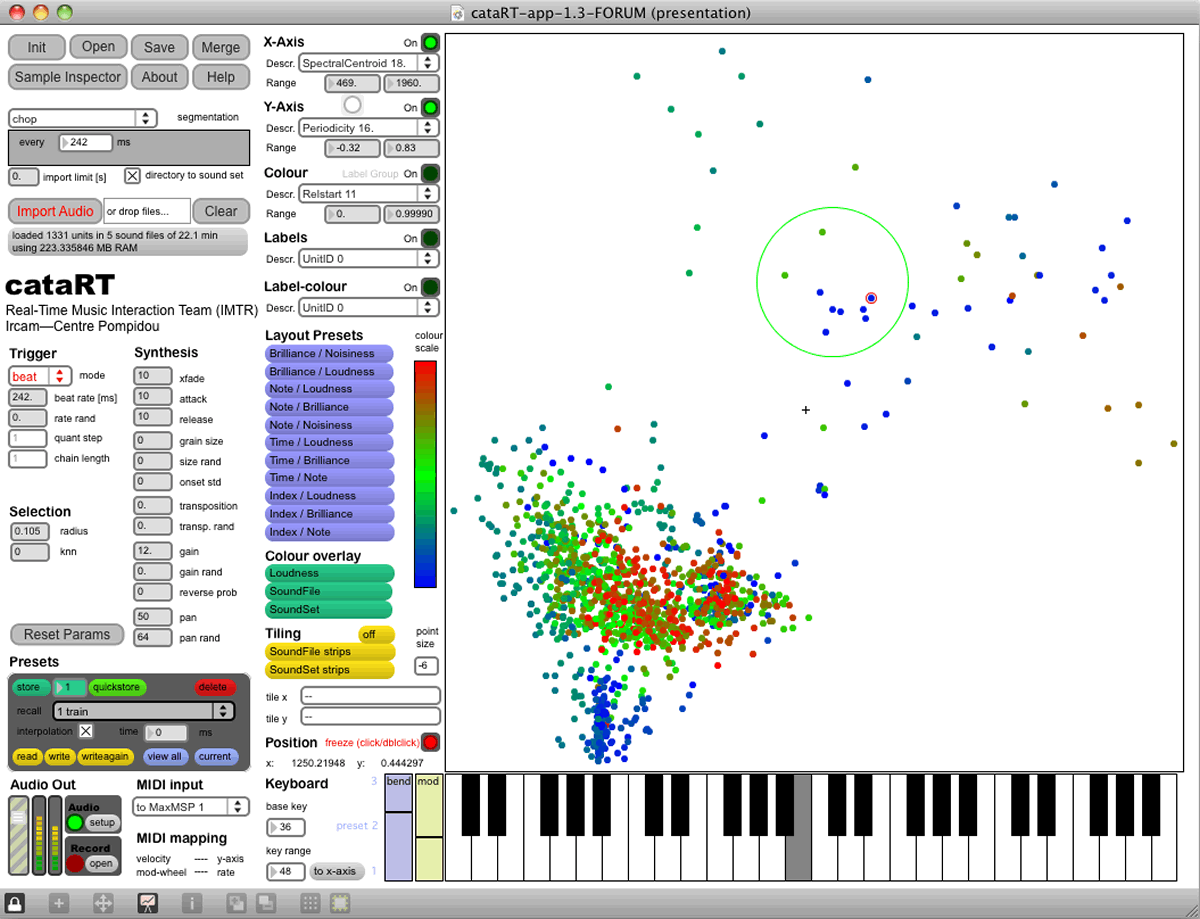
Corpus-based concatenative synthesis methods (CBCS) are used more and more often in various contexts of music composition, live performance, audiovisual sound design and installations (Schwarz 2007). They take advantage of the rich and ever larger sound databases available today to assemble sounds by interactive real-time or offline content-based selection and concatenation. Especially when environmental or instrumental recordings or live-recorded audio are used to constitute the corpus, the richness and fine details of the original sounds can be made available for musical expression.
CBCS is based on the segmentation and description of the timbral characteristics of the sounds in the corpus, and on their synthesis by selection of sound segments from the database matching sound characteristics given by the user. It allows the user to explore a corpus of sounds interactively or by composing paths in the descriptor space, and to recreate novel timbral evolutions. CBCS can also be seen as a content-based extension of granular synthesis, providing direct access to specific sound characteristics.
It has been implemented in various systems and environments, and is the subject of an on-going survey of existing systems and research (Schwarz 2006). The author’s own implementation since 2005 is an interactive sound synthesis system named CataRT (Schwarz et al. 2006) that can be run in Max/MSP with the FTM&Co. extensions, in a new implementation based on the MuBu library (Schnell et al. 2009) or as a standalone application. 1[1. Visit the ISMM team’s website at IRCAM for more information on CataRT and MuBu, as well as the bibliographic survey of work using corpus-based concatenative sound synthesis.]
While the research has until recently focused mainly on the analysis and synthesis methods, and handling of the corpus, current research now turns more and more towards how expert musicians, designers, the general public or children can interact efficiently and creatively with a corpus of sounds.
The use of CBCS as a new interface for musical expression (NIME) or digital musical instrument (DMI) for use in live performance by expert musicians introduces an important and novel concept that is the essence of the interface — the space of sound characteristics with which the player interacts by navigating through it, with the help of gestural controllers.
Principle and Motivation of CBCS
Corpus-based concatenative synthesis systems build up a database of pre-recorded or live-recorded sound by segmenting it into units, usually of the size of a note, grain, phoneme or beat, and analysing them for a number of sound descriptors, which describe their sonic characteristics. These descriptors are typically pitch, loudness, brilliance, noisiness, spectral shape, etc., or metadata such as instrument class, phoneme label, etc., that are attributed to the units and also include critical information about the segmentation of the units: start time, duration, source sound file index. These sound units are then stored in a database (the corpus). For synthesis, units are selected from the database that are closest to given target values for some of the descriptors, usually in the sense of a weighted Euclidean distance.

Ever larger sound databases exist on all of our hard disks and are waiting to be exploited for synthesis, a task that is less and less feasible to do completely manually given this increase in size. Therefore, the help of automated sound description will allow the user to access and exploit a mass of sounds more efficiently and interactively, unlike traditional query-oriented sound databases (Schwarz and Schnell 2009).
As with each new synthesis method, corpus-based concatenative synthesis gives rise to new sonorities and new methods to organize and access them, and thus expands the limits of sound art. Here, by selecting snippets of a large database of pre-recorded sound by navigating through a space where each snippet is assigned a place according to its sonic character (Video 2), it allows to explore a corpus of sounds interactively, or by composing this path, and to create novel sound structures by recombining the sound events, proposing novel combinations and evolutions of the source material. The metaphor for composition is an explorative navigation through the sonic landscape of the corpus.
Last, using concatenative synthesis, as opposed to pure synthesis from a signal or physical model, allows a composer to exploit the richness of detail of recorded sound while retaining efficient control of the acoustic result by using perceptually and musically meaningful descriptors to specify the desired target sound features.
Interacting by Gestural Control
In a DMI context interacting with gesture sensors to control the navigation through the sound space, each combination of input device and synthesis mode redefines the affordances of the interaction and thus in fact constitutes a separate digital musical instrument (Schwarz 2012). The controllers fall into two groups: positional control in 2D or 3D and control by analysis of audio input (see next section). 2[2. A collection of video and audio examples showing the use of CataRT as a musical instrument can be found on the IMTR web page.]
The most intuitive access to navigating the corpus is provided by XY controllers, such as MIDI control pads, joystick controllers, etc., for giving the target position in 2D (Video 3). Better still are pressure-sensitive XY controllers such as a graphics tablet, or some rare Tactex-based controllers, that additionally allow for the control of dynamics. Multi-touch controllers or touchscreens, especially when pressure sensitive, are the dream interface for navigation, providing an intuitive polyphonic access to a sound space (Video 4).
Motion capture systems, using either cameras and markers or depth-sensing cameras, offer a full-body access to a sound corpus mapped into physical 3D space. These interfaces have not yet been frequently used for music performance, but are beginning to be used in installation settings (Caramiaux et al. 2011, Savary et al. 2013).
Accelerometer-equipped devices such as game controllers, smartphones or tablets can be used to navigate the 2D space by tilting and shaking. Examples showing the use of accelerometers built into a device to navigate the corpus can be seen in Video 3 (starting at 4:50).
How and when the units close to the target position are actually played is subject to the chosen trigger mode that, together with the control device, finally determines the gestural interaction. There are two classes of trigger modes that give rise to two different styles of musical interaction. We will analyse these two modes according to Cadoz’s framework (Cadoz 1988; Cadoz and Wanderley 2000), which distinguishes three types of gesture: excitation, selection and modification.

With dynamic instrumental gestures, the specification of the target position can at the same time trigger the playback of the unit. Clearly, here the navigation in the sound space constitutes a selection gesture, and in this group of trigger modes it is at the same time an excitation gesture.
The other class of trigger modes separate selection from excitation, giving rise to continuous rhythms or textures. The navigational gestures are solely selection gestures, while no excitation gestures are needed, since the system plays continuously. However, the trigger rate and the granular playback parameters can be controlled by modification gestures on faders.
Interacting by Audio Input
When CBCS is controlled by descriptors analysed from audio input, it can be used to transform sound in surprising ways, for example, to create augmented instruments or to transcribe and re-orchestrate environmental sound (Einbond et al. 2009). This special case of CBCS is generally called audio mosaicing.
The ability to map input descriptors to target descriptors is a significant improvement over the control of CBCS using audio spectrum analysis, as in the case of classical audio mosaicing, where the selection is made by direct similarity between input and corpus spectra.
In a DMI context, we can make use of piezo pickups on various surfaces that allow the user to hit, scratch and strum the corpus of sound, exploiting its variability according to the gestural interaction, the sound of which is analysed and mapped to the 2D navigation space. This is demonstrated in Video 5: piezo mics are placed beneath the cover of a corrugated plastic folder, and the hands are used to play a corpus of metallic sounds. Dull, soft hitting selects sounds in the lower left corner of the corpus descriptor space where sounds are more dampened or dull, while sharp, hard hitting plays more in the upper right corner, where more edgy and sharp sounds reside.
This mode of gestural control in particular often creates a gestural analogy to playing an acoustic instrument, especially in a duo improvisation setting.
In a compositional context, corpus-based analysis and selection algorithms can be used as a tool for computer-assisted composition. In recent research by Einbond, Schwarz and Bresson (2009), a corpus of audio files was chosen that corresponded to samples of a desired instrumentation. Units from this corpus were then matched to a given target. Instead of triggering audio synthesis, the descriptors corresponding to the selected units and the times at which they are selected were then imported into a compositional environment where they were converted symbolically into a notated score (Video 6) that approximates the target, which could be an audio file, analyzed as above or symbolic: an abstract gesture in descriptor space and time.

Live Recording the Corpus
For live performance, especially in an improvisation involving both an instrumental and a CBCS performer, recording the corpus live from the acoustic instrument creates a stronger and more direct coupling between the acoustic and the digital performer, compared to improvisation without exchange of sounds. Whereas in the latter the coupling takes place in an abstract space of musical intentions and actions, live CBCS creates a situation in which both performers share the same sound corpus (Audio 1). Thus, the coupling takes place in a concrete sound space, since the very timbral variation of the acoustic performer directly constitutes the instrument from which the digital performer creates music by navigation and recontextualisation (Schwarz and Brunet 2008; Johnson and Schwarz 2011).
This setting could even be seen as an improvisation with two brains and four hands controlling one shared symbolic instrument — the sound space — built up from nothing and nourished in unplanned ways by the sound of the acoustic instrument, explored and consumed with whatever the live instant filled it with. It creates a symbiotic relationship between the acoustic and digital performers.
This principle of using only sounds provided by the other performer was also employed in the author’s duo performance with Roger Dean at the SI13 conference concert in November 2013. However, the symmetry of two laptop performers suggested that the principle be realised here by a previous two-way exchange of base sound material the performers had been using in their respective solo pieces preceding the duo (Audio 2).
Interaction for an Installation Audience
CBCS also found very promising application in environmental sound texture synthesis (Schwarz and Schnell 2010; Schwarz 2011) for audio-visual production in cinema and games, as well as in sound installations such as the Dirty Tangible Interfaces (DIRTI), which opens up discovery and interaction with rich sound corpora to the general public and children (De Götzen and Serafin 2007).

Dirty Tangible Interfaces (Savary et al. 2012, 2013) offer a new concept in interface design that forgoes the dogma of repeatability in favour of a richer and more complex experience, constantly evolving, never reversible and infinitely modifiable. In the first realisation of this concept, a granular or liquid interaction material placed in a glass dish (Fig. 2) is tracked for its 3D relief and dynamic changes applied to it by the user(s).
The interface allows the user to interact with complex, high-dimensional datasets using a natural gestural palette and with interactions that stimulate the senses. The interaction is tangible and embodied using the full surface of the hands, giving rich tactile feedback through the complex physical properties of the interaction material (Videos 8 and 9).
While related work exists that superficially resembles DIRTI — notably SandScape, Relief and Recompose (all three developed at MIT 3[3. More information about and demonstrations of the SandScape, Relief and Recompose are available on the webpages of the MIT-based Tangible Media Group.]) — the guiding principles differ radically. Such interfaces are neither aimed at expressivity nor made for fast, embodied interaction as is needed in musical performance. Further, the precise (re)configuration of the interface is the aim, in contrast to the DIRTI principle of flexibility. Also, they use expensive (laser scanning) or custom-built sensor technology, whereas DIRTI is outfitted with more affordable “hardware” such as commodity webcams and kitchen glassware.
The water-based Splash Controller organic UI (Geurts and Abeele 2012) is closer to DIRTI’s concept, detecting the manipulation of water in a gaming context, while Tom Gerhardt’s mud-based design project, the Mud Tub, comes quite close but lacks the multi-dimensionality and musical application. 4[4. For a demonstration of the Mud Tub, see YouTube video “Tom Gerhardt — Mud Tub, Tangible Interface 2009” (4:22) posted by “MediaArtTube” on 19 February 2010.] The only slightly dirty musical interfaces are PebbleBox and CrumbleBag (O’Modhrain and Essl 2004). Those examples of a granular interaction paradigm are based on the analysis of the sounds resulting from the manipulation of physical grains of arbitrary material. This analysis extracts parameters such as grain rate, grain amplitude and grain density, which are then used to control the granulation of sound samples in real time. This approach shows a way of linking the haptic sensation and the control of granular sounds. However, this interface focuses on the interaction sound and does not extract information from the configuration of the material.
Optimization of the Interaction Space
While a direct projection of the high-dimensional descriptor space to the low-dimensional navigation space has the advantage of conserving the musically meaningful descriptors as axes (e.g., linear note pitch to the right, rising spectral centroid upwards), we can see in Video 2 (starting around 1:00) that sometimes the navigation space is not optimally exploited, since some regions of it stay empty, while other regions contain a high density of units that are hard to access individually. Especially for the XY controller in a multi-touch setting, a lot of the (expensive and always too small) interaction surface can remain unexploited. Therefore, we apply a distribution algorithm (Lallemand and Schwarz 2011) that spreads the points out using iterative Delaunay triangulation and a mass-spring model (Video 10).

Discussion and Conclusion
From the variety of examples and usages, we can see that using corpus-based approaches allows composers and musicians to work with an enormous wealth of sounds, while still retaining precise control about their exploitation. From the author’s ongoing experience and observation of various usages we can conclude that CBCS and CataRT can be sonically neutral and transparent, i.e., neither the method nor its software implementation come with a typical sound that is imposed on the musician, but instead, the sound depends mostly on the sonic base material in the corpus and the gestural control of selection, at least when the granular processing tools and transformations are used judiciously. As a DMI, it allows expressive musical play, and to be reactive to co-musicians, especially when using live CBCS.
A more general questioning of the concept of the sound space as interface is the antagonism of large variety vs. fine nuances that need to be accommodated by the interface. Indeed, the small physical size of current controllers does not always provide a sufficiently high resolution to precisely exploit fine nuances. Here, prepared sound sets and zooming could help, but finally, maybe less is more: smaller, more homogeneous corpora could encourage more play with the minute details of the sound space.
One weakness in the typical interaction setup is that the interface relies on visual feedback to support the navigation in the sound space. This feedback is typically provided on a computer screen that is positioned separate from the gestural controller (except for the multi-touch screens), thus breaking the co-location of information and action. For fixed corpora, this weakness can be circumvented by memorizing the layout and practising with the corpora for a piece, as has been shown in the author’s interpretation of composer Emmanuelle Gibello’s Boucle #1. In such cases, the computer screen is hidden from the performer’s view, so that he can base his interpretation solely on the sound, without being distracted by information on the screen, and can thus engage completely with the sound space he creates, and with the audience.
For future research and development in efficient interaction with a corpus of sound, application of machine-learning methods seem to be most promising. These could assist in classification of the input gesture in order to make accessible corresponding classes in the corpus, or adaptive mappings between corpora (Stowell and Plumbley 2010) to increase the usability of audio control. More advanced gesture analysis and recognition could lead to more expressivity and definition of different playing styles, and spatial interaction in an installation setting is largely left to explore.
Bibliography
Beckhaus, Steffi, Roland Schröder-Kroll and Martin Berghoff. “Back to the Sandbox: Playful interaction with granules landscapes.” TEI 2008. Proceedings of the ACM’s 2nd International Conference on Tangible and Embedded Interaction (Bonn, Germany: B IT Center, 18–20 February 2008), pp. 141–144. http://www.tei-conf.org/08
Bonardi, Alain, Francis Rousseaux, Diemo Schwarz, Benjamin Roadley. “La collection numérique comme modèle pour la synthèse sonore, la composition et l’exploration multimédia interactives.” Musimédiane 6 (2011). http://www.musimediane.com/numero6/COLLECTIONS
Cadoz, Claude. “Instrumental Gesture And Musical Composition.” ICMC 1988. Proceedings of the International Computer Music Conference (Köln, Germany: GMIMIK, 1988), pp. 1–12.
Cadoz, Claude and Marcelo M. Wanderley. “Gesture—Music.” Trends in Gestural Control of Music. Edited by Marcelo M. Wanderley and Marc Battier. Paris: Ircam, 2000.
Caramiaux, Baptiste, Sarah Fdili Alaoui, Tifanie Bouchara, Gaétan Parseihian and Marc Rébillat. “Gestural Auditory and Visual Interactive Platform.” DAFx-11. Proceedings of the 14th International Conference on Digital Audio Effects (Paris, France: IRCAM, 19–23 September 2011). http://dafx11.ircam.fr
De Götzen, Amalia and Stefania Serafin. “Prolegomena to Sonic Toys.” SMC 2007. Proceedings of the Sound and Music Computing Conference (Lefkada, Greece: University of Athens, 11–13 July 2007). http://smc07.uoa.gr/SMC07 Proceedings.htm
Einbond, Aaron, Diemo Schwarz and Jean Bresson. “Corpus-Based Transcription as an Approach to the Compositional Control of Timbre.” ICMC 2009. Proceedings of the International Computer Music Conference (Montréal: McGill University — Schulich School of Music and the Centre for Research in Music Media and Technology [CIRMMT], 16–21 August 2009).
Geurts, Luc and Vero Vanden Abeele. “Splash controllers: Game controllers involving the uncareful manipulation of water.” TEI 2012. Proceedings of the ACM’s 6th International Conference on Tangible, Embedded and Embodied Interaction (Kingston ON, Canada: Queen's Human Media Lab, 19–21 February 2012), pp. 183–186. http://www.tei-conf.org/12
Johnson, Victoria and Diemo Schwarz. “Improvising with Corpus-Based Concatenative Synthesis.” In the Proccedings of (Re)thinking Improvisation: International Sessions on Artistic Research in Music (Malmö, Sweden: Malmö Academy of Music, 25–30 November 2011).
Lallemand, Ianis and Diemo Schwarz. “Interaction-Optimized Sound Database Representation.” DAFx-11. Proceedings of the 14th International Conference on Digital Audio Effects (Paris, France: IRCAM, 19–23 September 2011). http://dafx11.ircam.fr
Leithinger, Daniel and Hiroshi Ishii (2010). “Relief: A Scalable Actuated Shape Display.” TEI 2010. Proceedings of the ACM’s 4th International Conference on Tangible, Embedded and Embodied Interaction (Cambridge MA, USA: MIT Media Lab, 25–27 January 2010), pp. 221–222. http://www.tei-conf.org/10
Leithinger, Daniel, David Lakatos, Anthony DeVincenzi, Matthew Blackshaw and Ishii Hiroshi. “Recompose: Direct and gestural interaction with an actuated surface.” Siggraph 2011: “Emerging Technologies”. Proceedings of the 38th International Conference and Exhibition on Computer Graphics and Interactive Technologies (Vancouver, Canada, 9–11 August 2011), p. 13. http://www.siggraph.org/s2011
_____. “Direct and Gestural Interaction with Relief: A 2.5D shape display.” UIST ’11. Proceedings of the 24th ACM Symposium on User Interface Software and Technology (Santa Barbara CA, USA, 16–19 October 2011), pp. 541–548.
O’Modhrain, Sile and Georg Essl. “PebbleBox and CrumbleBag: Tactile interfaces for granular synthesis.” NIME 2004. Proceedings of the 4th International Conference on New Instruments for Musical Expression (Hamamatsu, Japan: Shizuoka University of Art and Culture, 3–5 June 2004), pp. 74–79. http://www.nime.org/2004
Reed, Michael. “Prototyping Digital Clay as an Active Material.” TEI 2009. Proceedings of the ACM’s 3rd International Conference on Tangible and Embedded Interaction (Cambridge, UK: 16–18 February 2009), pp. 339–342. http://www.tei-conf.org/09
Savary, Mattieu, Diemo Schwarz and Denis Pellerin. “DIRTI — Dirty Tangible Interfaces.” NIME 2012. Proceedings of the 12th International Conference on New Interfaces for Musical Expression (Ann Arbor MI, USA: University of Michigan at Ann Arbor, 21–23 May 2012), pp. 347–350. http://www.eecs.umich.edu/nime2012
Savary, Mattieu, Diemo Schwarz, Denis Pellerin, Florence Massin, Christian Jacquemin and Roland Cahen. “Dirty Tangible Interfaces — Expressive Control of Computers with True Grit.” CHI 2013 — Changing Perspectives. Proceedings of the ACM’s 2013 Conference on Human Factors in Computing Systems (Paris, France: 27 April – 2 May 2013), pp. 2991–2994. http://chi2013.acm.org
Schnell, Norbert, Axel Röbel, Diemo Schwarz, Geoffroy Peeters and Riccardo Borghesi. “MuBu & Friends — Assembling tools for content based real-time interactive audio processing in Max/MSP.” ICMC 2009. Proceedings of the International Computer Music Conference (Montréal: McGill University — Schulich School of Music and the Centre for Research in Music Media and Technology [CIRMMT], 16–21 August 2009).
Schwarz, Diemo. “Concatenative Sound Synthesis: The early years.” Journal of New Music Research 35/1 (2006) “Audio Mosaicing,” pp. 3–22.
_____. “Corpus-Based Concatenative Synthesis.” IEEE Signal Processing Magazine 24/2 (March 2007), pp. 92–104.
_____. “State of the Art in Sound Texture Synthesis.” DAFx-11. Proceedings of the 14th International Conference on Digital Audio Effects (Paris, France: IRCAM, 19–23 September 2011). http://dafx11.ircam.fr
_____. “The Sound Space as Musical Instrument: Playing corpus-based concatenative synthesis.” NIME 2012. Proceedings of the 12th International Conference on New Interfaces for Musical Expression (Ann Arbor MI, USA: University of Michigan at Ann Arbor, 21–23 May 2012). http://www.eecs.umich.edu/nime2012
Schwarz, Diemo, Grégory Beller, Bruno Verbrugghe and Sam Britton. “Real-Time Corpus-Based Concatenative Synthesis with CataRT.” DAFx-06. Proceedings of the 9th International Conference on Digital Audio Effects (Montréal QC, Canada: Schulich School of Music, McGill University, 18–20 September 2006), pp. 279–282. http://www.dafx.ca
Schwarz, Diemo and Eteinne Brunet. theconcatenator Placard XP edit. CD track in Leonardo Music Journal 18 (December 2008) “Why Live? — Performance in the Age of Digital Reproduction.”
Schwarz, Diemo and Norbert Schnell. “Sound Search by Content-Based Navigation in Large Databases.” SMC 2009. Proceedings of the 6th Sound and Music Computing Conference (Porto, Portugal: Casa da Música, 18–20 July 2009), pp. 253–258. http://smc2009.smcnetwork.org
_____. Descriptor-based sound texture sampling. SMC 2010. Proceedings of the 7th Sound and Music Computing Conference (Barcelona: Universitat Pompeu Fabra, 21–24 July 2010), pp. 510–515. http://smc2010.smcnetwork.org
Stowell, Dan and Mark D. Plumbley. Timbre remapping through a regression tree technique.” SMC 2010. Proceedings of the 7th Sound and Music Computing Conference (Barcelona: Universitat Pompeu Fabra, 21–24 July 2010). http://smc2010.smcnetwork.org
Vogt, Florian, Timothy Chen, Reynald Hoskinson and Sidney Fels. “A Malleable Surface Touch Interface.” Siggraph 2004. Proceedings of the 31st International Conference on Computer Graphics and Interactive Technologies (Los Angeles CA, USA, 8–12 August 2004), p. 36. http://www.siggraph.org/s2004
Social top