[Keynote]
The Final Frontier?
Spatial strategies in acousmatic composition and performance
According to the musical history books, especially those in English or German, the most significant achievement of the electroacoustic medium was to add to music the means to control timbre and space. In actual fact, acousmatic music opened up far more than this — not least, a whole new paradigm for handling and interacting with sound directly, instead of through a system of notation. Yet, more than 60 years after Schaeffer, composers and theoreticians are still trying to find the vocabulary and methodologies for thinking about and discussing the issues involved in a medium whose poetic, language and materials range far beyond what was previously available under the label of “music”. In particular, the issue of “space” — its meaning, handling and importance — all but ignored outside acousmatic music, continues to divide practitioners, who cannot even agree whether it is part of the compositional process or merely an issue of performance practice.
Introduction (and Some History!)
The voice-over for a certain popular and long-running TV science fiction series announcing space as “the final frontier” could — perhaps perversely — be taken as a reference to one of the major concerns of music in the second half of the 20th century. Whilst not exactly a completely new phenomenon, it is fair to say that the majority of the western musical canon in not particularly concerned with aspects of space. The very use of the word ensemble to describe a group of musicians already clearly implies that those musicians are likely to be grouped together in one place. And when space does become a feature of a piece of music, it is mostly in a supplementary, rather than central role — a function of architecture in the case of the antiphonal motets composed for St Mark’s, Venice; a function of an extra-musical programme in 19th-century orchestral repertoire; a function of the narrative in opera and music drama.
In the second half of the 20th century, however, space did become an important musical issue in its own right, something worthy of formalised integration into musical thinking. This came about in two ways. The first was essentially the result of threads of development already taking place within western music — specifically Schoenberg’s rationalisation of ever-expanding chromaticism into the 12‑note row and, ultimately, via Webern’s refinement of Schoenberg’s method, to the integral serialism of the European avant-garde after the Second World War.
Following this line of musical evolution, it is not difficult to see how integral serialism could regard the organisation of space according to a fixed set of serially determined proportions as no less logical than the serial organisation of the parameters of pitch, duration, dynamic and even timbre. In serial thinking, the primary agent of definition is the interval between events. So, just as we can perceive intervals in the various parameters — between two pitches, between two durational values, between two dynamic levels, and between the timbre of two different instruments — so, the serial composer argued, it is valid to differentiate, at a structural level, between sounds originating “over here” and those emanating from “over there”. The measurement of physical space is just another interval in a musical world whose logic and coherence is largely predicated on the distance between things rather than on the attributes and characteristics of the things themselves. In other words, this is a quantitative view of music, and it is no surprise that notation underpins this concept of what music is. In reality, of course, musical phenomena such as frequency are continua. Dividing them up into discrete steps, such as the 12 equal semitones of the tempered scale, may make them easier to notate; but then it is notation, rather than sound that becomes the rationalising component of musical structure and, ultimately, defines what is and isn’t “music”. I have difficulties with this view, because it challenges sound as the primary experience and the primary definer of music.
The second way in which space emerged as an important factor in music is less clearly articulated in the standard English language histories of music because, not only does it come from outside the central European, Austro-Germanic musical mainstream which so dominates the Anglophone understanding of the subject, but actually from outside music altogether. I am talking here about the single most significant development for and in music in the 20th century (far more important and fundamental than the breakdown of tonality and the emergence of serialism, for example); I am talking about sound recording.
The ability to capture sound seems at first to have only what we might call a documentary application in music — the recording of significant performances being the obvious case. But recording opens a wide new range of possibilities for our creative interaction with sound events, for composition using recorded sound materials. Firstly, and most dramatically, we need no longer be limited to using only those sounds previously defined as musical — that is to say, sounds exhibiting periodicity in their waveforms, to the extent that steady-state pitch and timbre are their dominant characteristics; any sound that can be recorded (and that is any sound at all) becomes potential compositional material.
Secondly, we can alter the way in which we play back a recording, thereby modifying our perception of the sound. Most obviously, playing back a recording at a different speed from the one at which it was made creates a transposition, but not in the same way as an instrument playing different pitches. In the case of the instrument, the transient characteristics of the attack remain broadly similar across its range (this is one of the ways we can still recognise it at the same instrument); in the case of changing the playback speed of a recording to yield a pitch two octaves lower than the original, the attack portion of the sound is stretch to four times its original length, completely altering the nature of the sound and the way we perceive it — it has, in fact become a new sound (especially as its timbre is also altered by the transposition of the bandwidth limitations of the original recording format). Changing the direction of playback creates an even more confusing situation: a reversed recording of a piano note, for example, may not initially be recognisable as a piano note at all — the attack, which is one of the predominant characteristics of a piano sound, is completely missing at first, and when it finally arrives (reversed), we may recognise the source only whilst simultaneously realising that the sound is actually impossible in the physical world.
Thirdly, the possibility of repeated listening via recordings changes our understanding of, and relationship with, the sound material. To take a simple illustration; when we hear a violinist play a short phrase once, we hear the phrase; if we hear the same player play the same phrase again, we experience recognition — “that was the same phrase played a second time.” Western music has always used this simple fact to build comprehensible musical structures; all standard musical forms involve repetition to aid listener-orientation. If we record our violinist’s two performances of the phrase, however, and now listen to the recordings repeatedly, the more intensive listening experience reveals two related facts: firstly, the two renditions of the phrase are not “the same” at all, despite their notational (quantitative) identity and their consequent assumed equivalence in standard analytical methods; and secondly, the two recordings have subtle, qualitative differences which give them distinct characters: grain and blemishes which we don’t normally hear on one listening — subtle differences of intonation, vibrato, weighting, stress, tempo, duration and dynamic.
The measurement of physical space is [for the serialists] just another interval in a musical world whose logic and coherence is largely predicated on the distance between things rather than on the attributes and characteristics of the things themselves.
Our recordings therefore point out both the ability of the ear/brain mechanism to ignore sonic artefacts which we know culturally not to be part of the phrase (like the person next to you coughing or turning the pages of the programme book at a concert) and the ability of the microphone to reveal to us aspects of sound we cannot normally access — a feature which can be taken to further extremes by placing mics much closer to sound sources than we might normally be able (or care!) to place our ears. We can thus deduce that, most of the time, we listen to music in what might be considered normal circumstances (and certainly in the way music was, de facto, listened to in the days before the microphone), we listen from outside. The kind of measurements on which serialism (and even, arguably, tonality) depend can only really be observed by standing outside the material. Repeated listenings to recordings (particularly, but not only, with ultra-close microphone placement) permits us to listen to the interior of the sound, to be inside it. It also raises the question of whether there might be a music based on this internal uniqueness of each recorded sound event.
Well, of course, there is a music which does just this. In 1948, Pierre Schaeffer (whose background was in radio production and engineering rather than in music) began examining and manipulating sound recordings, experimenting ways of changing the sounds and re-recording the results. Without having the time to explore the history of musique concrète here, I do want to tease out a few observations about it and, in particular, to contrast it with the approach taken in the elektronische Musik produced in the studios founded slightly later in Cologne (and I should warn those of a nervous disposition that I am likely to be outrageously dismissive of one school and fiercely complimentary about the other!).
Without wishing to labour the point, I would say that the European avant-garde, despite its protestations to the contrary, merely continued what we might call the traditional western musical paradigm, building demonstrably coherent, convergent structures out of the relationships (or intervals) between elements in what the serialists called the various parameters. The only essential difference was that the organisational base was now serial, rather than tonal, as it had been for the previous three centuries or so. And serial music, like its tonal predecessor, claimed its authority from the score. But because western notation cannot include all the nuances we know to exist in music (remember our violinist), notation became the normative factor in determining what music was; music was legitimised by notation, not by sound — as Trevor Wishart has pointed out, even what is thinkable in music is then determined by what can be notated. The complexities of serial organisation led to the strange situation that if, for example, a listener cannot perceive the serial organisation of dynamics in Klavierstück I because the pianist cannot accurately realise the five dynamic levels contained in the (simultaneously struck) nine-note chord at the bottom of page 1, then the piece becomes, in a very real sense, meaningless. Enter the Cologne electronic studio, where dynamic precision could be obtained by mixing elements of the correct amplitudes together (we’ll leave the perceptual question to our consciences!). The studio also offered the means to extend serial control to the realm of timbre by adding sine tones together. Of course, in order to do this, one has to determine the serial proportions, so measurement and quantitative thinking still dominate the compositional landscape; the “objective truth” of the score is taken as documentation of the composer’s thought. Being readily susceptible to measurement, notation has enabled generations of analysts and musicologists to persuade us that musical value resides entirely in architectonic, quantitative criteria which are assumed to be and can be proved by the score to be, part of a conceptual construct which precedes sound. I challenge this view of music, offering instead organic, qualitative criteria for musical construction, based on the perceptual realities found in sound material itself — and this is the precise basis of musique concrète.
I’d just like to take this opportunity to tackle another historical over-simplification as well. The term musique concrète has often been taken to mean only that the sounds used were “real”, recorded from acoustic sources via microphone — perhaps true enough at the outset, but the use of the boy’s voice in Gesang der Jünglinge and the integration of analogue synthesis modules into the GRM studios soon blurred the distinctions. What I feel is perhaps more important, however, is that the method of working and, by extension, the relationship between composer and material are also concrete — i.e., physical. As in the plastic arts, the composer works directly with the material itself, rather than at one remove, via the intermediate layer of notation and its resultant logic. In the early days, this relationship was manifest in the shaping of material (its dynamic profile or envelope, for example) through the use of physical gestures performed on physical interfaces; I shall return to the question of performance presently.
Provenance and Directionality; Movement and Trajectory
But first, I need to return to what is supposed to be the central topic of this Address — space. It seems to me that a few things need to be said about what might actually characterise space in acousmatic composition. If we adopt the serial line, we can see that it’s clearly about expressing an interval in the parameter of space, just as there are intervals in pitch, duration and amplitude which are meaningful in terms of the work’s structure. In this case, it’s important to understand where the sound originates, in order to be able to measure the distance from there to the point of origin of another sound. This is what we might call provenance, and it gives rise to an approach that privileges the point source, the point of origin of the sound. In music of this tradition, directionality matters because it allows us to measure these spatial intervals. It is likely (though these characteristics do not always coincide) that in music descended from this serial way of thinking, the sound might well be mono, might well be synthetic and might well have no context beyond itself — it exists, effectively, in a vacuum (if you will pardon my poetic bending of the laws of physics!).
Contrast this with recorded sounds, especially sounds recorded in at least 2 channels. In a stereo studio recording, there is space within the sound — to some extent, the sound provides its own context. This sense of space might be manifested as static (for example, different frequency nodes within a single resonating body might be spatially separated) or moving (for example, the rolling around of a golf ball inside a bodhrán).
In environmental recordings, the target sound (if there is one; the entire environment might be the target) exists within a larger sound field, within which one might equally have static events (birds singing in the dawn chorus, for example) or moving ones (the flapping of a bird’s wings as it flies past the microphones).
So, whilst I refute the simplistic notion that musique concrète and elektronische Musik are defined merely by their source material — real, recorded sounds in the case of the former and electronically generated sounds in the case of the latter — there is nevertheless an underlying truth concerning spatial aspects of the two approaches, reflected in the relative ease of using, as the basis of composing in the studio, microphone recordings made in stereo, whilst stereo synthesis is somewhat more complex. Studio recordings in stereo offer possibilities of internal movements that we can’t normally hear with the naked ear; stereo environmental recordings offer some sense of the target sound (if there is one!) within a context.
Why are stereo recordings better than mono? The first answer is: phase. The sense of movement in a recording, I would suggest, is perceived by the listener as being real because of the phase shifts encoded within the source recording by the two microphones; simply panning a mono sound within a stereo field cannot emulate this sense of reality (which is not to say that panning can never be compositionally effective!). A second aspect of what we might term “recorded space” is that our focus is probably more on the nature and quality of the recorded sound field and of any movement within it than with the values and intervals (what I think of as quantities) of the precise locations or start and finish positions of events. In other words, capturing spatial behaviours (by recording in at least stereo) tends towards an attitude to space that is, once again, more qualitative than quantitative, more organic than architectonic. And these characteristics are found more often in acousmatic music descended from the tradition of musique concrète than in music in the elektronische Musik tradition.
In my own work, I am more concerned with the quality, behaviour and character of space as an organic entity, than with its precise measurement. It is more important for me that listeners hear that the sound moves in a particular manner, with a certain speed and energy, than to know where it moves from and to. I think of space — and especially movement within the space of the work — much more in terms of the energy characteristics of the sound event. Just as a sound has energy trajectories in frequency and amplitude, so it has a parallel energy profile of motion. Slowly evolving drones with relatively long onsets and releases are unlikely to flit rapidly about in space; short, lively wisps of sound might — in fact, possibly must — behave in this fashion, with the precise locations visited being less significant than the erratic character of the motion; and I find it virtually impossible to describe this type of sound without moving my body in an appropriate way.
So I never record source material in mono — always stereo; I can always render a stereo recording to mono if I need to, but turning a mono recording into convincing stereo is much harder. Recording in more channels — 8, for example — is not all that easy, even in the studio, and extremely problematic in the field. Options like ambisonic recording and double M‑S arguably capture more of the full soundfield, but I tend to adopt a more practical, pragmatic approach, and record in simple stereo (preferably M‑S, as it offers more control of the spatial balance back in the studio than X‑Y mic techniques), and then use some decent processing in the studio to enhance the spatial effect to create the sense that the sound exists in more than just stereo. Turning stereo recordings into believable 8‑channel material (for example) is one of the primary objectives of the BEASTtools suite of Max/MSP patches we have developed in recent years. 1[1. The BEASTtools suite is available for download in the research section of the BEAST website.]
Believability and Image
In the abstract, I described acousmatic music as “a medium whose poetic, language and materials range far beyond what was previously available under the label of ‘music’.” I am, of course, referring here to the ways in which acousmatic music can quote from the real world in ways that instrumental and vocal music can only approximate; unlike Beethoven, I could incorporate the sound of a real cuckoo in a work if I wanted to, simply by using a recording. But real situations are also strongly characterised by their spatial characteristics and behaviours. Believability, which is something I use as a compositional strategy, is partly delivered by spatial means.
When I talk about believability in my music, I do not necessarily mean that the sound is, in fact, a real, unadulterated take or a slice of reality (though it could be) — I’m not talking about documentary recordings or even soundscape composition. What I’m looking for is that something which we might describe as a scene in a work could be real; it’s believable in the sense of being plausible, physically possible, even if it’s in fact entirely phoney and artificially constructed (i.e. composed!). For this reason, you won’t find many instances of backwards (reversed) sounds in my work, because they are physically impossible. I am drawn to, and even my more abstract pieces are populated predominantly with, sound materials that could (and probably did originally) exist in the real world. Even if they are heavily processed, so that their origins are obscured, their behaviours somehow seem to comply with the laws of physics. I like sounds that have internal energy (water, friction, etc.), sounds that are in a continual state of evolution, renewal and transformation even before I get my hands on them. I’m attracted to sounds that have a tactile quality; I also like the sense of latent human agency or intervention that emanates from certain types of sound materials.
For all these reasons, I think of space mostly in terms of images. An image could be a single sound, recorded in the studio; it could be a straight environmental field recording. More often than not, in my music it is a hybridised amalgam of materials composed together to go beyond simple representation. This approach also enables me to exploit ambiguity to the full, constructing scenes which contain real-world events, but also containing elements which relate to some aspects of the scene through spectromorphological links (Smalley) and which are therefore believable in that context, but do not strictly belong in the scene in a real-world sense. The alien sound can then become the agent through which I can “turn a corner” out of that scene into something else — a process which I describe as changing locations “at the speed of sound.” An image could also be a sound or sounds behaving in a particular way or ways within a field. This definition also, of course, embraces those sounds’ spatial behaviours.
So, to summarise: sounds seem to me to want to behave according to their energy content. I tend to think of this in holistic terms (I use the word “articulation” as a general descriptor), but I admit that it can be broken down into aspects of frequency and spectrum, amplitude, duration and spatial behaviour (which look suspiciously like those old serial parameters, though I don’t think of them in that way). My job as a composer is not to impose my will on sound materials, but to work in partnership with them, interrogating them via processing and the contextualisation of other sounds — finding ways of allowing them to reveal (and revel in) their intrinsic characteristics and energy profiles in ways that seem natural and fitting for the sounds. I’m not saying that one can never make a sound do something “out of character” — one can; but this, in my own case, is probably the exception rather than the rule and is usually extremely significant in terms of the musical discourse. A “real” sound departing from the norm and behaving artificially is yet another weapon in the armoury of the acousmatic composer.
Composition and Performance
As I have said, I am more concerned with the quality or character of images (intimate, diffuse, high, etc.) or movement (erratic, stately, direct) than about their measurement (the precise location of the distance and speed travelled). This also carries through into the field of performance, where what I am trying to do is to animate the images within the work, echoing the nature and character of their spectral, rhythmic, dynamic and spatial energies, rather than trying to place specific events “here” or “there”. Sound diffusion is often thought to be about space alone (indeed, it is often referred to as “spatialisation”, though I don’t like this term, as it implies that the sound material lacks spatial information — which, if it was recorded in stereo, it most likely will not), but in my view, diffusion is at least as much about phrasing and shaping the musical events — gestures and textures — according to all their musical characteristics, not just the spatial ones. I think this is especially true of acousmatic music descended from the tradition of musique concrète; works in the tradition of elektronische Musik have historically attempted to find more precise, reproducible modes of performance.
Indeed, I’m not entirely sure where composition stops and performance begins. We are now so used to having limitless numbers of audio tracks that we forget that composers not so long ago had to do multiple sub-mixes to achieve complex textures and events — and that meant performing those sub-mixes in the studio, in real time, over and over again until they got them right.
Performance Practice 1: Stereo Diffusion
The time has come for a brief overview of what diffusion is and why it is necessary. Before getting on to the specifically spatial aspects, I’d just like to remind those of us old enough to remember, and inform those of us who have only entered the acousmatic fray since the advent of the digital era, that for most of the 60-odd years of its history, acousmatic music was created and stored on analogue tape. This is a very imperfect medium, with a severely restricted signal-to-noise ratio (about 63 dB, I seem to recall, even with a professional tape recorder, though this could be increased to about 72 dB with noise reduction systems like Dolby‑A) — and that was for the first generation recording! Tape hiss, the noise floor in question, is unavoidable in the analogue recording process; more problematic still was the fact that copying the original recording would add a second layer of noise. Each successive copy added more and more noise, such that a 20th generation copy (because of sub-mixing, etc.) was likely to be unusable and elaborate strategies and careful planning had to be used to try to avoid unnecessary copying of material.
Moving to more obviously space-related issues, let us first of all remember that sound propagates through a medium — this already has spatial associations. Moreover, sound implies space within itself, via the frequency domain — we don’t use the words “high” and “low” (which are spatial terms) in this respect for no reason. Our human experience associates low rumbling sounds with slow moving, heavy objects such as larger animals, trucks, etc., that tend to have a location near the ground, and higher, brighter sounds with lighter objects that have the possibility of leaving the ground, such as birds, insects, etc. 2[2. Please don’t mention the Boeing 747 — of course there are exceptions to this gross generalisation!] So some sense of depth and distance exists, even in a mono recording — though it is better in stereo, whose obvious benefit is that it creates, potentially, an image that exists between and behind the two loudspeakers. Lateral placement and motion are easily represented and robust; depth and distance can be created by using lower levels, high frequency attenuation, reverberation and possibly a reduced lateral spread, to imply sound approaching the vanishing point — i.e. perspective, which is not available in mono. But this is much more fragile. Whilst the illusion (for artifice it usually is) works well over a good pair of loudspeakers in a controlled listening space, playback of the same image in a large, public listening space 3[3. Whether we want to continue with this historical mode of “concert” delivery at all is a moot point, but not one we have time for here.], the coherence of the image begins to suffer through the expanded dimensions and the probably unruly acoustic properties of the listening space. And this is where diffusion comes in.
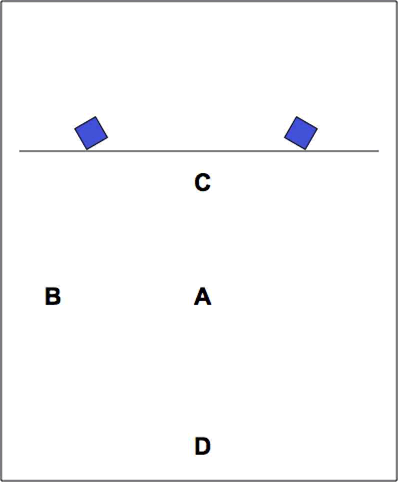
At the most basic level, diffusion could be described as active intervention to enhance the sound image(s) on the storage medium and to render those images more “readable” in a space. As well as enlarging the dynamic range, making quiet sounds quieter and louder sounds louder, lateral movement could be exaggerated and distance cues, hinted at in virtual terms on the tape, made actual in the listening space. This is all achieved by using multiple pairs of speakers for the playback of stereo sources. I’d like to illustrate this by reference to the approach taken within BEAST during the 80s and 90s.
Even on a good hi-fi system, with the listener in the sweet spot, the stability of the stereo image is notoriously fickle — turning or inclining the head, or moving to left or right by just a few inches, can cause all kinds of involuntary shifts in the image. So if a stereo piece is played only over a single pair of loudspeakers in a large hall (which will probably also have a significant reverberation time), the image will be even less stable and controllable than in a domestic space, and will certainly not be the same for everyone in the audience. In the equivalent of the ideal listening position at home (Fig. 1, position A), everything is relatively fine, but elsewhere the story is very different. Listeners at the extreme left or right of the audience (position B) will receive a very unbalanced image; someone on the front row (position C) will have a “hole in the middle” effect, whilst a listener on the back row (position D) is, to all intents and purposes, hearing a mono signal! Listener C will also experience everything as “close”, with listener D hearing it as “distant”, simply because these listeners are in those real relationships with the loudspeaker cabinets. The shape and size of the hall have a huge influence on how marked these effects will be. But in any public space, some or all of these effects will occur for a large majority of the audience. Events carefully oriented by the composer within the space of the stereo stage will simply not “read” in a concert hall unless something more radical is done.
BEAST (Birmingham ElectroAcoustic Sound Theatre)
Here we have the beginnings of such a radical solution — what in BEAST is called the “main eight”, which I regard as the absolute minimum for the playback of stereo tapes, represented in dark blue in Figure 2. This refers to the system as it was for most of the 1990s. The original stereo pair from the previous diagram is narrowed to give a real focus to the image via the Mains (A); this removes the hole in the middle, enhances intimacy and offers the effect of “soloist” speakers. A Wide pair (B) is added so that dramatic lateral movement can be perceived by everyone. In a stereo BEAST system, these four speakers would normally be of the same type (ATC) and driven by matching amplifiers (approximately 500 watts each) as this frontal arc represents the orientation for which our ears are most sensitive to spectral imbalance among loudspeakers; they are set slightly above ear height. The rest of the system consists of speakers from various manufacturers with differing characteristics (Genelecs, Tannoys, Volts, KEFs), driven by 500, 250 or 100-watt amplifiers, depending on the speaker itself and its function in the system in that particular space.
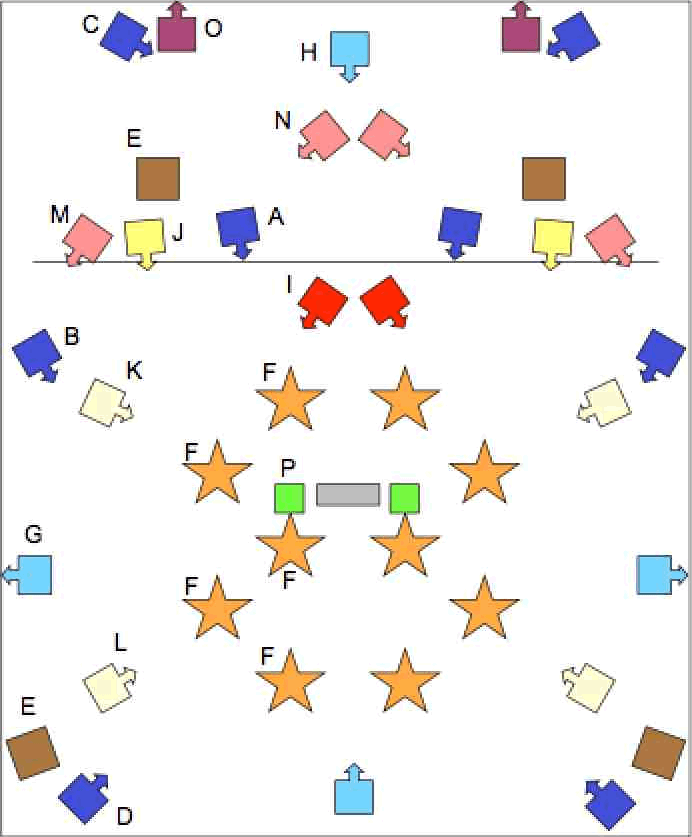
For effects of distance (which on the original stereo tape are implied by careful balancing of amplitude, spectral and reverberation characteristics, and which are very susceptible to being drowned by actual concert hall acoustics), it is useful to be able to move the sound from close to distant in reality, following the cue on the tape — hence the Distant pair (C). These are angled quite severely across the space to hold the stereo image in a plane behind the Mains. This off-axis deployment also reduces the treble, adding to the distant effect (high frequency energy dies faster over greater distances than low frequency energy). They are usually on towers at least 2 meters above ear height. The Rear pair (D), also positioned above ear height, helps fill the space, adding a sense of being enveloped in sound. Implications of circular motion on the tape can actually be made to move round the room, and the introduction of sounds behind the listener can still have a startling effect.
After the Main Eight, the next most significant additions to a system would be Subwoofers (E, brown), crossed-over at around 80 Hz and probably with a roll-off of 18 dB/octave (BEAST started with just two of these and added two more later on), and Tweeters (F, orange), suspended over the audience in up to ten stars of six units each (possibly plus a wide dispersion unit for each star) and around 6 feet in diameter. These speakers extend down to 1 kHz, so they are filtered to ensure that they only receive the top octave or so, to enhance, rather than confuse, the overall spatial image.
Beyond this, the number and positioning of loudspeakers is primarily a function of the concert space. Long, thin halls may need Side Fills (G, light blue), to achieve smooth transitions from frontal to rear sound (these are often angled up and/or reflecting off the side walls so that the audience is less aware of the “headphone” effect). In wide halls, a stereo pair of Front/Back (H, light blue) speakers positioned quite high in the stage centre and centrally behind the audience can be useful in overcoming the effect of having a “hole in the middle” (and creates the possibility of cruciform patterns with the Wides or Side Fills). Punch speakers (I, red), central at the front of the stage and slightly outward-pointing but placed fairly low for maximum impact, can be useful for sforzando reinforcement of strong articulation.
Height can also be used to good effect. Proscenium speakers (J, yellow) hanging over the front edge of the stage add verticality to the frontal image. If the hall has lighting gantries, then Front Roof and Rear Roof (K/L, beige) speakers enable front/rear motion via a canopy, rather than by moving the sound only round the edges of the hall in the horizontal plane. Differing heights can be further exploited by angling speakers on the Stage Edge (M, pink) down to the floor in an attempt to create the illusion of sound originating from a lower level. Flood speakers (N, pink), positioned close together on the floor in the centre of the stage and pointing out to cause the sound to reflect off the side walls, can create the effect of filling the space without strong localisation.
In short halls, it can sometimes be difficult to achieve a real sense of distance, but if the wall at the back of the stage is brick or stone, Very Distant speakers (O, plum) facing away from the audience and reflecting off the wall can be effective, the high frequency attenuation and general reduction in source location delivering remarkably well the sensation of distance. Finally, in extremely large halls, speakers placed immediately by the Mixer (P, light green) can help overcome the sensation that the sound is predominantly at the periphery of the listening space. Of course, not all of these speaker locations are always necessary — it depends entirely on the nature, character and sound of the performance space — but it would be wrong to assume that small halls necessarily require fewer speakers (in the rumours… concert series, which we promoted in a 100-seater hall in Birmingham during the 1990s, we regularly used 28 channels).
Fader Configuration (or “Yes, but how do you drive it?”)
In a “classical” analogue diffusion system, every speaker or group of paralleled speakers needs a separate channel of amplification controlled by a fader. In small systems this can be achieved by using the group faders, but for bigger systems, direct channel outputs are needed. This necessitates splitting the stereo signal out from the source and running several left/right signal cable pairs into successive pairs of inputs. BEAST developed an elegant way of achieving what is effectively a “mixer in reverse” (few in/many out) by using a switching matrix through which several incoming stereo signals can be routed (and mixed) to any stereo outputs, without re-plugging between pieces. The custom-built DACS 3‑D was a 12‑in (later 24) / 32‑out design, which allowed easy pre-configuration for multiple stereo sources, multi-channel operation and microphone mixes from secondary mixers when needed. It offered inserts on every channel for outboard EQ, and the outputs went via a multiway connector and a balanced multicore cable to the remote amplifier racks, which totalled at that time just over 7 kW of power.

The fader layout on the mixer raises interesting points in terms of ergonomics. In some systems, the most distant speakers in front of the audience are controlled by the leftmost pair of faders, the next most distant speakers by the next pair of faders, and so on, until the rearmost speakers are reached on the extreme right of the run of faders in use. This is a good configuration for certain kinds of motion (front to back, for example) but is less convenient for more dramatic articulation of material and space. BEAST has evolved a grouping of faders by function in any given performance space: the Main Eight are always in the centre of the console 4[4. This configuration, fortuitously, also happens to fit eight fingers on the faders, so sudden, dramatic gestures on these faders result in the most significant changes in spatial perception by the audience.], with subs and tweeters to the extreme left; beyond this, the layout varies according to the unique design of the system for that space or event. Figure 3 shows a typical fader layout used by BEAST in the 1990s for a 28‑channel system.
I do not have the space here to discuss techniques of diffusion performance itself: relative signal levels, how many speakers might be blended at any given moment in a piece, what rate of change or what kind of spatial motion is appropriate and effective for given pieces or sections of works — the things which articulate both the sounding surface and the deep structure of the music. These are musical questions, answered by knowing the individual pieces and getting to know the space in rehearsal. 5[5. This is of course also informed by knowing the system and by being willing to change loudspeaker positions during rehearsal — pragmatic, and economically difficult, as there is never enough time to rehearse in the actual performance space.] But it cannot be stressed too strongly that decisions about loudspeaker placement should be made with reference to musical, perceptual and practical considerations, not technical, conceptual or theoretical demands.
Suffice it to say that diffusion is not, as is sometimes suggested, merely a random moving around of the faders or a means of “showing off” for the performer. But there is good and bad diffusion, just as there are good and bad performances in all spheres of music. Good diffusion is attentive to both the moment to moment unfolding of the sonic surface of the work and its structure: diffusion strategies can be used to enhance the restatement of material heard earlier and it can certainly help build climactic moments in a work (“loud all the time” is probably bad diffusion!).
And Then Came 8‑Channel
So far we have only considered diffusion in relation to stereo works, as the majority of pieces, certainly in the analogue era, were composed in this format. Additionally, as well as causing significant cost challenges, using more than two channels could limit the number of performances. With the advent of digital technology, cheap digital multitrack recording machines and computer audio interfaces with multiple outputs offered low-cost and practical options for thinking beyond the two source channels of stereo.
Many manufacturers settled on 8 outputs for sound cards and 8‑channel works were made easily transportable by the availability of ADAT and Tascam digital tape recorder, so I shall focus on 8‑channel composition in the following remarks.
Multi-channel Composition; Multi-channel Image
There are many approaches to composing in 8 discrete channels, but most of them imply an extension of spatial thinking on the part of the composer — after all, composers are no longer restricted to the illusion of the stereo image, which exists only between and behind the two loudspeakers. With more speakers, fed with discrete audio sources, one can surely create more complex spatial images and explore spatial counterpoint more readily. Most 8‑channel works, therefore, are based on the premise that the 8 channels will drive 8 loudspeakers, set up in a particular configuration. As a result, the sonic images I discussed earlier are composed with that specific speaker set-up in mind, and any other configuration creates an immediate distortion of the images, or even their complete destruction.
My own first 8‑channel works, perhaps unsurprisingly, assumed that the 8 tracks would feed 8 speakers deployed in the BEAST Main Eight configuration (see above) of Distant, Main, Wide and Rear pairs. I soon discovered that this loudspeaker array was not universally available; many concert playback systems only offer 8 or 12 loudspeakers altogether and these might be in a completely different configuration, so sending Streams (1999) or Rock’n’Roll (2004) to festivals and promoters was a risky business!
But some interesting points arise here. Firstly, by taking the approach of a fixed number of channels to be played back over an equivalent number of loudspeakers, are composers not, once again, in danger of having too fixed a notion of the spatial character of their works? The flexibility offered by stereo diffusion to deliver images that are close, intimate, diffuse, distant, high, etc., by using multiple pairs of loudspeakers is, ironically, sacrificed in the name of progress. To combat this problem we might consider diffusing an 8‑channel work over multiple arrays of 8 loudspeakers to create distance, closeness, intimacy, height, etc., just as one can in diffusing stereo pieces. But here come the practical problem: if, when a stereo work is performed in a public concert, one requires something like 24 speakers (12 times the number of tracks on the support medium) to deliver the range of images appropriate to the music as outlined above, then, logically, one would require 96 speakers to do the equivalent for 8‑channel pieces.
Performance Practice 2: Multi-channel Diffusion
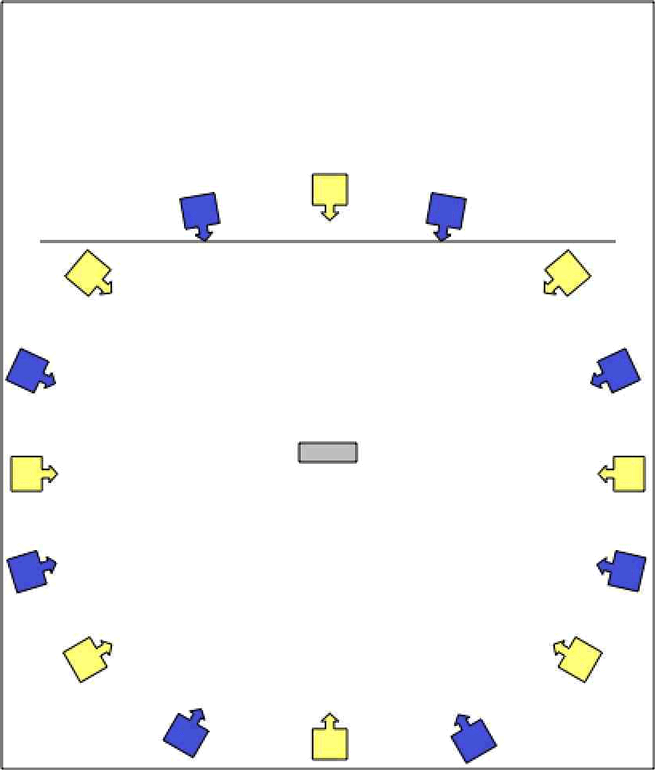
Once more, I would stress that my remarks here are predominantly about 8‑channel works, not 5.1, 7.1, 10.2, ambisonics, wavefield synthesis, etc. But 5.1 does have one thing going for it: it is a standard, and therefore, like stereo, it is a portable format. As I hinted above, 8‑channel, by contrast, has no agreed format of loudspeaker layout (and certainly no agreed standard of channel numbering, leading to further possible errors and distortions). Leaving aside the cube used by Stockhausen in Oktophonie (1990–91) and focusing on the horizontal plane alone, there are two commonly encountered configurations of a simple regular ring of 8 speakers, as shown by the blue (so-called “shoebox”) and yellow (“double-diamond”) arrays in Figure 4; unfortunately they are incompatible!
BEAST’s Approach to Handling Multi-channel Sources and Multi-format Concerts
BEAST’s first attempt at diffusing 8‑channel sources was in at its (belated) 20th anniversary weekend in 2003. I built a simple Max patch to allow control of multiple 8‑channel arrays, each from a single fader of a MIDI fader box, and the speaker set-up was similar to that shown in Fig. 5. The 8 Mains (A, dark blue) could be transformed into a Distant array (B, light blue) by replacing the front four speakers with four others. 6[6. The side and rear pairs are actually the same speakers for both rings, but this is less critical for delivering the distant image, as it is the signal in front of us that really seems to give the “distance” cue to the brain.] Then there are 8 High (C, light green) speakers mounted on elevated stands or on the lighting trussing over the audience and 8 Close speakers (D, dark green) at ear height. 7[7. These are actually offset into the “double-diamond” configuration shown by the yellow speakers in Fig. 4; interestingly, the incompatibility of this with the four pairs shown in blue in Fig. 4 seems less of an issue in larger systems!] Another offset array was positioned on a Gallery (E, yellow) that ran all round the hall.
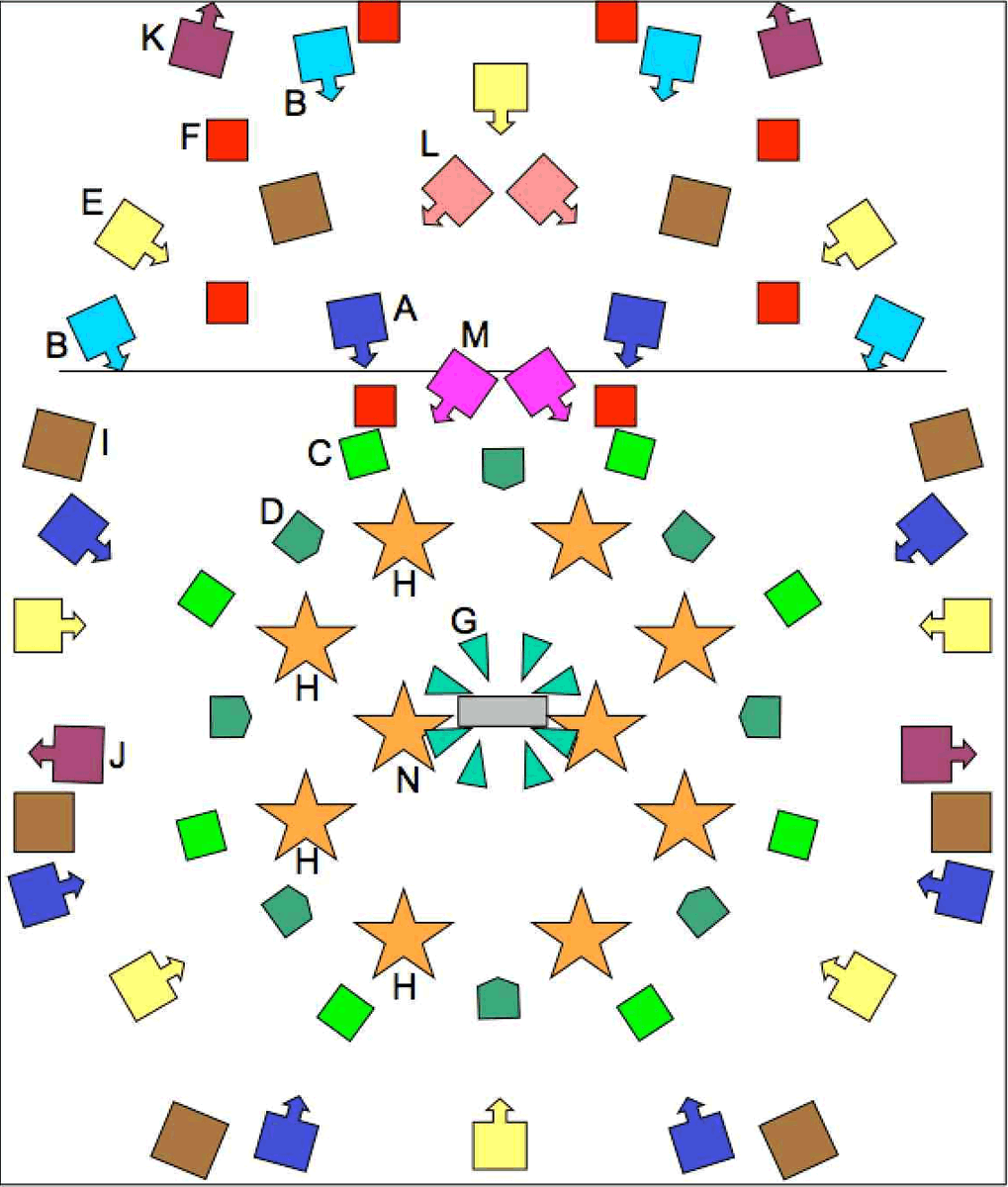
The Opera Stage array (F, red) was included because I had recently done a project with a choreographer in which sound material “followed” the dancer as she moved around the stage; clearly this needed always to remain in front of the listener to maintain the psychological link with the dancer, but it was interesting to note the effectiveness of the movement of sound alone within an 8‑channel “stage” that existed entirely in front of the audience. The two speakers nearest the audience are at ground level; the next two are set wider and higher; the next pair higher still; the two furthest away on the far wall are positioned behind the two on the floor but even higher — the plane formed by the whole array is therefore “tilted down” towards the audience in the same way that opera stages are often angled.
The 8 small speakers at the Desk position (G, aqua green) pointed outwards at around ear height (more recently, these have been replaced with just four speakers, still pointing out but at floor level, into each of which two source channels are mixed). Arrays of 8 Tweeters (H, orange) and 8 Subwoofers (I, brown) complete the 8‑channel rings. Of course, it is rare to have only 8-channel works in a concert, so some additional pairs — Side Fill (J, plum), Very Distant (K, plum), Flood (L, pink) and Punch (M, magenta) are normally included to deal with some of the problems discussed earlier and to offer special effects for stereo diffusion; e.g., as BEAST owns 10 arrays of 10 Tweeters, a final pair of these are often included for stereo works (N, orange).
More about Faders and “Driving the System”
Of course, if you are diffusing an 8‑channel piece using an analogue mixer or diffusion console, where each fader carries just one of the 8 signals, routed to one output/speaker, then even a simple cross-fade between one 8‑channel array and another requires becomes impossible, as it requires 16 fingers! The solution is to use a software-based system, in which the faders are merely controllers and no longer carry actual signal. It is then possible to assign a fader to control more than one channel — a stereo pair, an entire 5.1 or 8‑channel array, or subsets like the front half or all the left channels, etc. After our initial attempts using the Max patch mentioned above, with one fader per array of 8 speakers, we began to develop something altogether more flexible and sophisticated.
BEASTmulch
Between 2006 and 2008, BEAST was the main focus of a Research Project funded by the Wilson Arts and Humanities Research Council and led by my colleague Dr. Scott Wilson, with me as Co-investigator. One of the principal outcomes was the BEASTmulch (BEAST multi-channel) software, written in SuperCollider by Scott and PhD researcher Sergio Luque. The project tackled a wide range of issues surrounding the “Development of an intelligent software-controlled system for the diffusion of electroacoustic music on large arrays of mixed loudspeakers” (as it was jauntily titled). As well as enabling “normal” manual control, these included:
- routing;
- separation of audio and fader control functions;
- independent mapping of inputs, outputs, faders, etc.;
- the ability to scale to any size of system;
- various degrees of and approaches to automation, such as using target points in the music for recalling certain states or a sequence of pre-sets (similar to digital lighting boards);
- individual set-ups for different configurations, pieces and to accommodate performers’ preferences;
- specification of speaker position, including height (for techniques like VBAP; we were particularly keen to accommodate both pragmatic and idealised approaches to “space” — hence the incorporation of aspects of ambisonics, VBAP and other techniques);
- a suite of plug-ins to allow real-time control of many of these parameters;

Finally, the project also involved the development of a control surface (with Sukandar Kartadinata of Glui in Berlin) using motorised faders — a modular 32‑channel design based on the Gluion board, dubbed the MotorBEAST (Fig. 6).
We decided to use OSC because of problems of speed and resolution with MIDI controllers. For big concerts we normally use two MotorBEASTs; their minimal footprint, aided by needing only an Ethernet hub and a laptop in the centre of the auditorium, with everything connected to the main (remote) computer via Jollys VNC and a single Ethernet cable, means that the control position takes up only very few of the best seats! And, rather than make a visual spectacle of the act of diffusion by standing, we now sit to diffuse and try to focus the audience’s attention on the acousmatic listening situation. Extending this concern, we usually try to have some “atmospheric” lighting in our concerts (Fig. 7). Note that we do not light the individual loudspeakers, as this draws attention to them; what we are aiming for is that the loudspeakers also “disappear” as the sound image is sculpted in the space as an organic entity).
Further Refinements and some Technical Information


For the 2007 Øresundsbiennalen SoundAround festival in Copenhagen, we also had loudspeakers hanging from sections of aluminium lighting truss (Fig. 7). In that system, the tweeters were still suspended; now we often put them on the top of the trussing (Fig. 8), making the rigging of the system much easier and faster. This picture also shows a further development of the investigation of VBAP arrays: the use of “keystone” speakers to complete a dome-like structure — these top speakers should actually be higher than shown here (something we cannot achieve everywhere) so, if necessary, we delay the signal sent to them (another of BEASTmulch’s features) to make them appear further away from the audience.
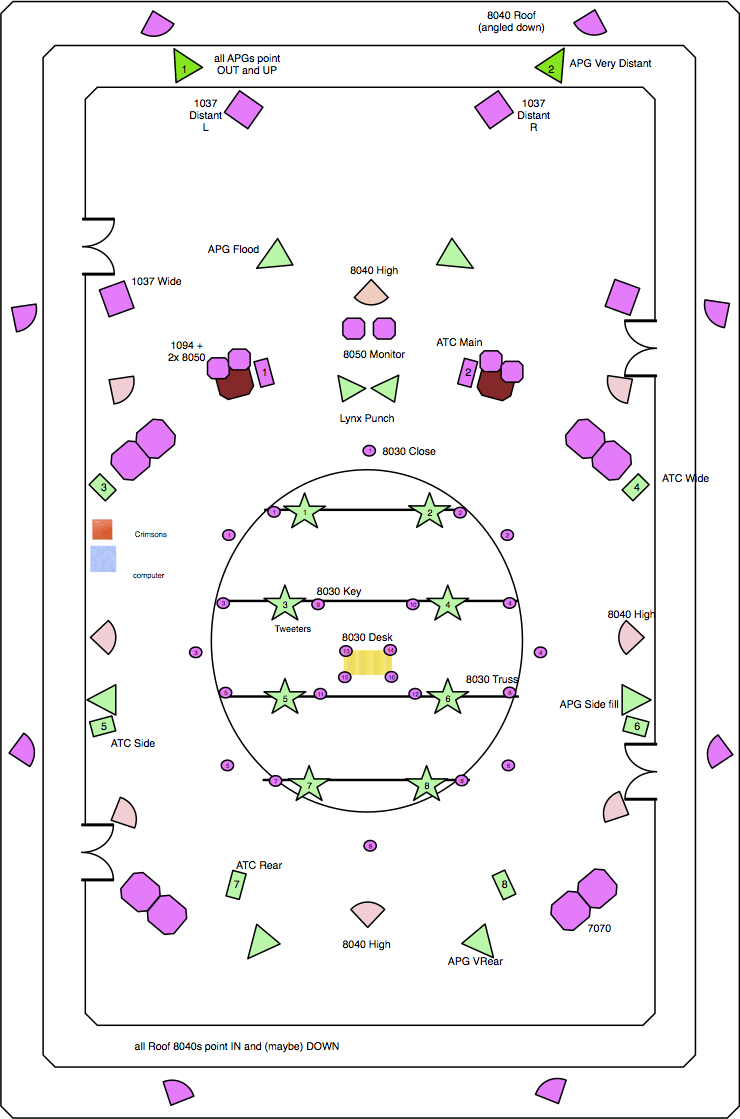
Because we now regularly install systems of more than 80 loudspeakers for concerts, and because the software needs to know what filtering to apply to which speakers (not only tweeters and subwoofers; some other speakers are filtered to optimise the sound), we now have to plan carefully the layout and positioning of all the speakers. This is particularly important if VBAP and other location-dependent techniques are being used. So I produce a “system map” (Fig. 9) showing the speaker positioning in the performance space; other members of BEAST turn this into output channel lists and maps of the “zoning” of speakers, in order to supply them with power and the correct signal cables via the shortest and most efficient routes. The “dome” is visible in this plan: 4 speakers on the floor at the desk (indicated by a yellow rectangle); 8 offset (double-diamond) at around ear-height; a high array on the trussing; and finally the 4 keystones. In this particular set-up, there is, in addition to this “close dome”, another, more distant dome-like array built around speakers on the two gallery levels and the crosswalks high up in the roof.
For the past few years, BEAST has used an Intel Mac tower with a MOTU PCI 424 card installed, capable of outputting to four MOTU 24 I/O units — 96 independent channels. This was the size of the system we ran in Berlin at the 1010 Inventionen festival (Fig. 10). We actually have more 24 I/Os and, as two PCI 424 cards can be installed in a single computer and addressed as an aggregate device, it is theoretically possible to address 192 discrete channels… but this is getting beyond even my sense of what is necessary for diffusion! However, remember that wavefield synthesis depends on literally hundreds of individually controlled loudspeakers — so maybe BEAST’s approach is not so extravagant! And it is more forgiving of the old adage that, if you want a sound to originate in a very specific location, then put a speaker there!
Performance and (back to) Composition

BEASTmulch was originally conceived and designed as software to assist in the performance of acousmatic music. But software like this also opens up new compositional possibilities — for example, a variation on the use of “stems” so common in film and commercial music production. With BEASTmulch you have the option of thinking in terms of stems for spatialisation — in other words, the source channels of a work, stored on the fixed medium, need not indicate a specific spatial deployment of speakers, but could be stems for subsequent spatialisation in real time during performance. This was my approach in BEASTory (2010), premiered at the Inventionen Festival in Berlin (Fig. 10), which was run from a 16‑channel file divided into multiple stereo stems, spatialised using BEASTmulch plug-ins and other options.
I feel it is important, therefore, to finish this paper by bringing us back to one of my earlier concerns — the relationship between composition and performance. I have always maintained that diffusion is, in a way, a continuation of the compositional process — the gestures on the storage medium are enlarged and enhanced to make them clear to an audience. But I have always found, even in the days when everything was stereo, that experience of diffusion has a strong impact on the compositional process: composers who diffuse think differently about composition.
I hope I have shown that tools like BEASTmulch also offer new ways of compositional thinking. But, as an afterthought, I’d like to add that at Birmingham we have also been working on BEASTtools, a set of modular, interconnectable Max patches and a package of overtly compositional tools which embody some of our experiences of space, of spatial composition and of sound diffusion. Like BEASTmulch, they are downloadable (for free!) from the BEAST website. 8[8. See the research section of the BEAST website for more information on BEASTtools, a “multichannel playground for the development of sound materials.”]
Social top