Gravikords and Pyrophones
The Reflexive Piano
Introduction
During my early work with interactive music systems (1998–2003), I focused on dataflow programming and neural network use for chord detection and other optimization problems. I gradually became interested in building a software system that would allow me to explore my voice as an improviser at the piano. Deeply influenced by the music of György Ligeti, and in particular his piano études, I sought analytical methods from computational musicology to derive data I could use in the algorithm’s design. I hoped that this algorithm could show me harmonic and rhythmic patterns and motivic nuances that I would otherwise miss. I used his work Der Zauberlehrling as the first data set.
Designing software systems that evolve their optimisation strategies in real-time takes, paradoxically, a very long time to get right. When such a system is trying to optimise a search for the best possible musical answer to a proposed musical question, it takes even longer as one must make inevitably disastrous mistakes and naïve choices as to what musical worlds to take into account, which notational and representational systems to employ, and what notions of “music” to allow the system to use as rules.
During the last six years, my research and performance practice have focused on building systems that combine genetic co-evolution with forms of spectral analysis, in order to build reflexive music algorithms. Very simply, these algorithms continually listen for musical input, and try to match incoming input with output of their own, relying only on timbre analysis instead of numerical representations of musical data such as MIDI.
This allowed me to use advanced analytical software tools such as Sonic Visualizer, a program for viewing and exploring audio data for semantic music analysis and annotation from Chris Cannam and Queen Mary, University of London. Also larger, more diverse frameworks, such as audioDB, a feature vector database management system for content-based multimedia retrieval that has been used for a variety of purposes such as distinguishing from hundreds of recorded performances of one Chopin Mazurka (Plans Casal and Casey 2010). audioDB was developed in order to unify treatment of content-based similarity search, and one of its integrated components, SoundSpotter, became the key ingredient of the algorithms I’ve designed.
It took some time to get to the point where I could use the system in live performance. During this time, I practiced, usually at a piano, by analysing small musical gestures and developing both a sense of the algorithm’s reaction to my playing, and my reaction to its behaviour. It is in no small measure due to my own initial ineptitude in programming complex artificial systems that Frank (named after Peter Todd’s seminal 2001 paper on using genetic co-evolution for musical composition) was initially a very inept improviser, being able only to mimic and stutteringly attempt to sound “alike” my own playing.
In this stage of design, I was attempting to leave behind the use of randomness as a structural determinant. As Arne Eigenfeldt pointed out in his own elucidation of the real-time composition versus improvisation problem (Eigenfeldt 2008), most early practitioners of interactive computer music such as David Behrman and George Lewis used “random methods to generate the requisite unpredictability.” Like Eigenfeldt, I wanted to use recomposition through analysis as the point of departure for my algorithm’s design, but unlike him, I didn’t want to rely on MIDI for codifying “the essence of what makes a good musical idea”; I chose instead to use timbre alone, and representations of analysed timbre segments as derived by SoundSpotter, formatted as MPEG7-described elements. A recent review of using timbre in the design of improvisation systems, including my own (Hsu 2010), outlined common practices in audio feature extraction and performance state characterization, and compared George Lewis’ system (Lewis 2000) to mine and others from a historical perspective. Readers interested in the lineage and detail of such systems will want to refer to Hsu’s excellent exposition of his timbre-aware ARHS improvisation system.
Strategies
Figure 1 illustrates the compositional strategy and process that I have come to follow when working with Frank.
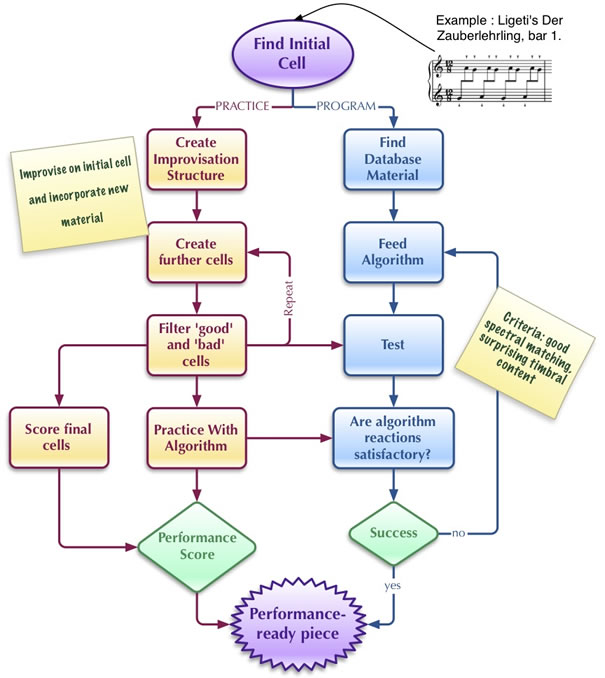
This compositional strategy is the result of having gone through perhaps hundreds of iterations during which I would attempt to find initial (seeding) material, and then using methods from computational musicology, created analyses of these that I could use as prototypical scores. In a second stage, I would observe the algorithm’s reactions to my playing, and adapt to those (or change the algorithm). This practice followed a basic set of steps:
- Analyzing scored music, listening to recordings of potential seed material, and performing analyses of these recordings;
- Extracting cells from analyzed materials (usually clusters of 1 to 4 bars) to begin to use in instrumental practice;
- Scoring results of instrumental practice, to make an improvisation “roadmap” that could be referred to later on as a unified piece.
Typically, the end result of the latter step was more of a mnemonic for my own improvisation than a score someone else could follow to re-create the piece. It was, as such, a way for me to get “back” to the piece. However, I have lately begun to create scores that are more complete frameworks for improvisation, and I will outline the process for these below.
In the first instance, comparing recorded versions of particular pieces such as Ligeti’s Der Zauberlehrling using linear-scale spectrograms (Fig. 2) generated using Sonic Visualizer.
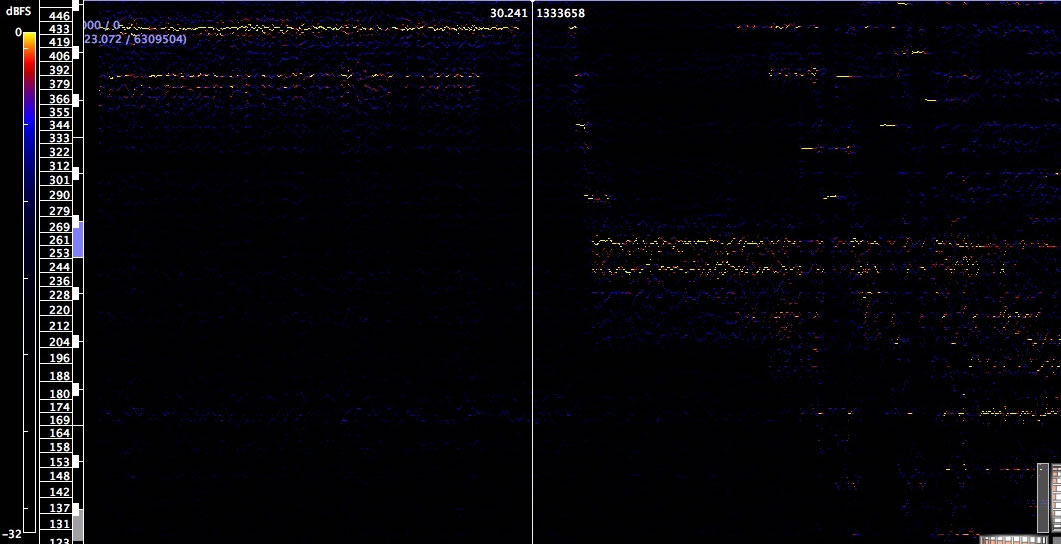
This gave me an initial pitch variance framework that I could then use to create Schenker-like graphs using the Lilypond music engraving system, which employs LaTeX and is extremely flexible for both extended notation and illustrating pitch class relationships. See Figure 3 for an example of such a score.
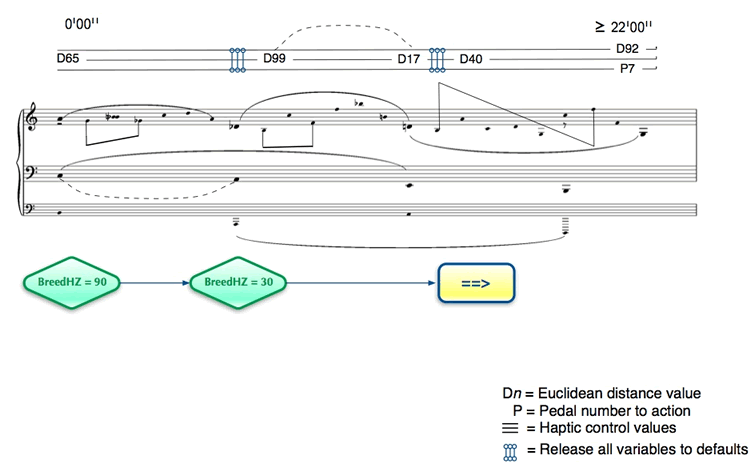
The following recording, made at Queen’s Sonic Arts Research Centre in Belfast, was recorded live and was an improvisation based on the score in Figure 3.
The Process
After performing analyses of potential seed material and finding improvisational cell materials in existing music or of my own creation, I typically construct an initial corpus of sound (the database that I will feed to the algorithm) and an initial improvisation framework.
Frank was written as a Pure Data external, so to use it in performance, I write PD patches that action the logistic steps that need to be taken for the evolution process to begin. The patch itself is not complex, as it tends to rely solely on methods described in C++ using the Flext framework (Grill 2005). There are a few checks to perform (this will apply to any person planning to extend Soundspotter as a framework for composition / improvisation): namely, that the object itself is loading within the Pure Data framework successfully. Watching the object loading messages in the PD console window can check this, as I was careful to write loading checks into the object code, including details of the window and hop size for FFT calculation. Figure 4 shows the console with Frank’s loading check in place.
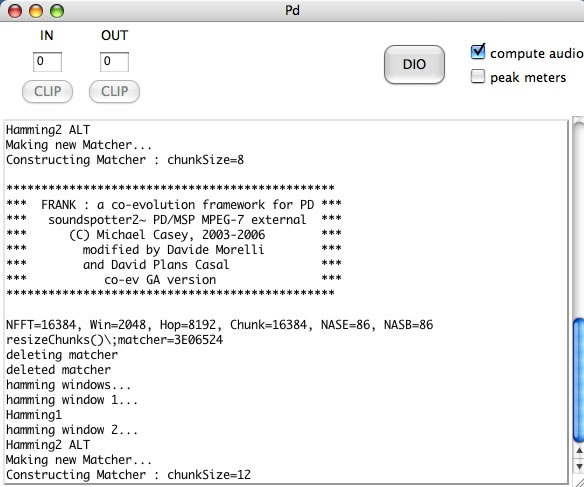
It’s worthwhile noting that right underneath the object loading message where one can read “FRANK: a co-evolution framework…,” one can also see:
NFFT=16384, Win=2048, Hop=8192, Chunk=16384, NASE=86, NASB=86
The first of these indicates the size of the FFT in vector size. While the others may be obvious (window size, hop size, etc.), the last one refers to the number of vectorial dimensions in the Absolute Spectrum Basis derived in MPEG7. This is 86-dimensional data, and in order for it to be used in my algorithmic design, I had to reduce its dimensionality. Early on, with by collaborator Davide Morelli (University of Pisa), we decided to use the k‑means algorithm to cluster this data. The IDs from each cluster were used as the initial genotype for the genetic co-evolution algorithm on which Frank relies.
Now, the patch can be written to load an audio database into a table, use this table to perform an analysis of static audio (a very large, flat WAV file). This can be done by using Soundspotter’s MATCH method, but that it can be also be done in real time using live audio by using the SPOT method, and in later incarnations of Soundspotter this is LIVESPOT.
Future Process
As a result of recent developments in embedding Pure Data as a library in other software frameworks, namely by Peter Brinkmann, Martin Roth, Peter Kirn and other developers and testers (Kirn 2010), as well as the Reality Jockey (RjDj) group, it is now possible to embed PD in iOS and Android applications, as well as any other audio-aware framework such as Open Frameworks (using portaudio, for example).
I am currently writing iPad-driven applications that will allow me to load (using libpd) Frank, and select a piece (a patch or series of PD patches) for performance. Having tested CPU performance and memory issues, and used it in rehearsals, it’s now clear that if one is conservative in the use of externals (which must be compiled and declared to libpd to work) and FFT calculations, it should be perfectly possible to use this system in live performance without the need for the traditional laptop, Pure Data, audio interface triumvirate. This will also allow for the distribution of pieces as iOS/Android apps, which anyone can download and use in concert, without the need for scores, recorded material, software distribution and platform version complexities that normally arise.
Gravikords and Pyrophones
Building such an algorithm felt, many times, like creating a new instrument. The piano started to become an extension of the initial process of analysis to such an extent that I begun to find it hard to find appropriate distance between the analytical and the improvisational. Even the interface of Sonic Visualizer’s own GUI, which contains a piano roll descriptive bar beside the spectrogram, reminded me of the monolithically imposing nature of the piano, its native segmentation, the frequency bands lined up in black and white.
I found escape from this by building my own instruments, the first of which, with help from luthier Siggi Abramzik, was an eight-string electric tap guitar similar to Emmett Chapman’s Stick, that allowed me to use the physical memory of the piano action to some extent, and a similar frequency range. But I could, at this point, slide and twang, change pickups and use diverse amplification, not to mention easily travel with it. Video 1 shows me playing this early instrument, opening for Scanner and Mira Calix at a Stockhausen tribute concert in 2007.


Having found Bart Hopkin’s book on experimental instrument design (Hopkin 1996), Gravikords, Whirlies & Pyrophones, and the Journal of Experimental Musical Instruments, I began to build chordophones of several different types. In the end, it may seem that my performance and research practice became an escape attempt from “pianism”, but this is not entirely accurate: pianos, especially good ones, offer pitch in extremely accurate bands (when well tuned), that are not only well-tempered, but homogeneous in timbre. Home-made instruments, especially home-made chordophones of dubious quality, offer chaotic timbre shapes and unpredictable tunings. When an algorithm’s entire raison d’être is to construct notions of musical similarity through timbre alone, the more complex and rich the timbre at the point of enquiry, the better.
Crowdsourcing the Corpus
Whilst initially having flat audio files as a corpus of sound Frank could navigate was good enough, I soon found that the analysis of recorded music as a process of recomposition could sometimes produce unsatisfying results. Building databases of navigable audio material, rendered navigable by analysis, meant that when presenting with repeatedly similar queries (in terms of timbre), the system answered back with similar answers. This is of course what the purpose of optimization is: to optimize a function until the answers are consistently good. In the end, the very design of the system became its downfall: predictability and exactitude are musically uninteresting.
Decomposing Acoustic Spectra
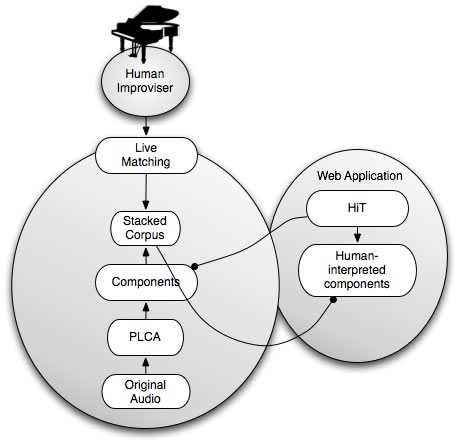
To try to get away from this, I decided I had to go back to my roots as a performer, and also to find dynamic ways of building timbrally interesting musical databases. As I outlined in recent work (Plans Casal and Casey 2010), I had begun to use component-wise decomposition of acoustic spectra, another computational musicology technique, in order to obtain a corpus of separated sound fragments. This approach was inspired by Bicycle Built for Two Thousand, a project by Aaron Koblin and Daniel Massey, in which crowd-sourcing of audio components as Human Interaction Tasks (HiT) in Amazon’s Mechanical Turk was used to rework the song Daisy Bell. A component-wise decomposition of Autumn in Warsaw, the sixth in György Ligeti’s 2nd Book of Piano Études, was used as the corpus. With each separated audio component from this corpus, as derived by Probabilistic Latent Component Analysis (PLCA) (Smaragdis 2007–09), I created Human Intelligence Tasks (HiTs) in the style of Amazon’s Mechanical Turk that would take each latent component from an original piece, randomly chosen, presented to the user to audition and then record their own version of it using voice or whatever instrument they wished to employ. As these were presented as a web application, I received thousands of submissions, each imitating a component. As in previous work (Plans Casal 2008, Plans Casal and Moreli 2007 and Plans Casal 2010), this was an attempt to build an improvisational / compositional framework that subsumed ideas from remixing and mashup culture, into the practice of computer music and algorithm-aided improvisation.
When gathered and sequenced in the right order, these components formed a re-synthesis of Ligeti’s original Étude, which I then used to build a music system for live performance using Frank. Instead of a flat database, this re-synthesized corpus contained emphases, accentual investments from each HiT interpreter, highlights of motivic analysis and note gestures that I couldn’t possible have found on my own. This humble exercise in crowdsourcing became large-scale analysis through composition, and opened my ears to a whole new practice: computational musicology techniques not only as information retrieval but also as compositional methodology. Figure 5 illustrates the data flow in the HiT system.
Improvisation/Composition Through Computational Musicology
In his article “Changing the Musical Object: Approaches to performance analysis,” Nicholas Cook put new methods for music performance analysis at the forefront of new musicology (Cook 2005), ascribing them enough importance to count as a step towards enlisting music “as a primary vehicle for the reinterpretation of culture and society” (Botstein 2002). In this article and others, Cook argues that writing performance into the mainstream of musicology may bring “New” musicology to maturity. I would further like to argue that new computational musicology methods can and should interbreed with new computer music / electroacoustic composition methods, including those where performance itself (especially in improvisatory practice) is one of the foci of analysis.
Bibliography
Botstein, Leon. “Cinderella; or Music and the Human Sciences: Unfootnoted Musings from the Margins.” Current Musicology 53 (1993), pp. 124–134.
Cook, Nicholas. 2005. “Changing the Musical Object: Approaches to performance analysis.” Music’s Intellectual History: Founders, Followers and Fads. Edited by Zdravko Blazekovic. New York: RILM (forthcoming).
Eigenfeldt, Arne. “Intelligent Real-time Composition.” eContact! 10.4 — Temps réel, improvisation et interactivité en électroacoustique / Live-electronics — Improvisation — Interactivity in Electroacoustics (October 2008). https://econtact.ca/10_4/eigenfeldt_realtime.html
Grill, Thomas. “Flext — C++ Layer for Cross-Platform Development of Max/MSP and PD Externals.” 2005. Slides available on the author’s website http://grrrr.org/research/publications
Hopkin, Bart. Gravikords, Whirlies & Pyrophones: Experimental Musical Instruments. Book + CD. Ellipsis Arts, 1996.
Hsu, William. “Strategies for Managing Timbre and Interaction in Automatic Improvisation Systems.” Leonardo Music Journal 20 (December 2010) “Improvisaton,” pp. 33–39.
Kirn, Peter. “libpd: Put Pure Data in Your App, On an iPhone or Android, and Everywhere, Free.” Create Digital Music. 21 October 2010. http://createdigitalmusic.com/2010/10/libpd-put-pure-data-in-your-app-on-an-iphone-or-android-and-everywhere-free [Last accessed 17 February 2011]
Lewis, George E. “Too Many Notes: Computers, Complexity and Culture in Voyager.” Leonardo Music Journal 10 (December 2000) pp. 33–39.
Plans Casal, David. “Time After Time: Short-circuiting The Emotional Distance Between Algorithm And Human Improvisors.” Proceedings of the International Computer Music Conference (ICMC) 2008 (Belfast: SARC — Sonic Arts Research Centre, Queen’s University Belfast, 24–29 August 2008).
_____. “Co-evolution and MPEG7 Matching in Creating Artificial Music Improvisors.” Music as It Could Be: New Musical Worlds from Artificial Life. Edited by Eduardo Reck Miranda. Middleton WI: A-R Editions, 2010.
Plans Casal, David and Michael Casey. “Decomposing Autumn: A Component-Wise Recomposition.” Proceedings of the International Computer Music Conference (ICMC) 2010 (New York: Stony Brook University, 1–5 June 2010).
Plans Casal, David and Davide Morelli. “Remembering the Future: An Overview of Co-Evolution in Musical Improvisation.” Proceedings of the International Computer Music Conference (ICMC) 2007: Immersed Music (Copenhagen, Denmark, 27–31 August 2007).
Rhodes, Christophe, Tim Crawford, Michael Casey and Mark d’Inverno. “Exploring Music Databases at Different Scales using AudioDB.” Journal of New Music Research 39/4 (2010), pp. 337–348.
Smaragdis, Paris and Bhiksha Raj. “Shift-Invariant Probabilistic Latent Component Analysis.” Boston: Mitsubishi Electric Research Laboratories (MERL), 2007–09. Available on the MERL website http://www.merl.com/publications/TR2007-009
Social top