“One at a Time by Voice”
Performing with the voice-controlled interface for digital musical instruments
The Voice-Controlled Interface for Digital Musical Instruments is a controller conceptually designed to be an extension to traditional touch-based musical interfaces. It allows simultaneous control of an arbitrary number of instrument parameters by variation of the performer vocal sound timbre. The generative and adaptive dual-layer mapping strategy makes an extensive use of unsupervised machine learning and dimensionality reduction techniques to compute voice map for musical control. The aim is to maximize the breadth of an ad hoc explorable perceptual sonic space of specific digital musical instruments. The system achieves this by dimensionality reduction of the instrument control space and adaptation to the vocal characteristics of the performer. In this paper we present firstly a high level overview of the system, then application and user perspective of the interface. We describe the procedure to train and setup the system as well as the available user options and their effects on the interface response and instrument interaction. Finally, we introduce a performance exclusively based on the Voice-Controlled Interface, in which one instrument at a time is driven by the performer’s voice, recorded and then looped, building up an improvised composition.
A distinguishing and intrinsic feature of digital musical instruments (DMI) is the physical independence of the sound generation component from the interface, despite the specific synthesis algorithm and the user input modality. This has promoted the proliferation of novel musical interfaces, mapping strategies and instrument control techniques, described and formalized in a plethora of articles published since the mid-1990s. 1[1. See, for example: Wessel and Wright 2001; Dahlstedt 2001, Arfib and Kessous 2002, Paradiso and O’Modhrain 2003; Wanderley and Depalle 2004; Miranda and Wanderley 2006.] Moreover, improvements on specifications and high availability of general-purpose computers, software development tools, software libraries, communication protocols, sensors and hardware development kits have drastically streamlined the implementation process of musical interfaces. These improvements have also reduced the range of necessary skills for the designer, while constantly enhancing the musical interfacing potential. However, the concurrent use of multiple interfaces in musical performance is rarely addressed in literature. The majority of musical interfaces require performer hand interaction (touch, haptic, gestural), which is and expressive and reliable. However, this redundancy in the user input modality across interfaces represents a bottleneck in the flow of musical intention into sonic realization, or rather a limit in the number of events and parameters simultaneously controllable by the user (Fasciani and Wyse 2012a). In this context the performer’s voice can often be considered as a “spare bandwidth” (Cook 2009), hence used as an extra source of gesture to ease this limitation, which is more crucial in performances where a one individual or a small group of performers controls a large setup of DMIs.
Several controllers using voice as the input modality has been proposed in previous work and Stefano Fasciani has reviewed the existing literature highlighting application and limitation of the proposed approaches (Fasciani 2014). The majority of the work reviewed presents technical or conceptual design issues, or is limited to a specific use context. Some propose closed and stand-alone interfaces with no tuning options, which conflicts with the growing needs of performers for personalization, configurability, versatility and integration offered by other control devices that are not voice-driven. Others present naïve mappings that simply map characteristics of the vocal apparatus (such as pitch and intensity) onto an homologous synthesis algorithm. Moreover, they generally fail to cope with the different vocal tract characteristics of different users; instrumental expressivity, in terms of sonic manipulation, is still an issue. As a result, the number of performers making regular use of voice-control techniques is still very limited.
The Voice-Controlled Interface for Digital Musical Instruments (VCI4DMI) aims to be generic and adaptive to implement ad hoc interfaces for any sound generation or processing device. We consider it as an extension more than an alternative to traditional touch-based interfaces. The cognitive complexity required to simultaneously use the VCI4DMI and another traditional interface is particularly low since we can easily perform other actions while speaking or singing. The target of the vocal control is an arbitrary number of real-valued and time-continuous instrument parameters. Therefore, the VCI4DMI maps continuous gestural parameters to continuous musical parameters (Kvifte and Jensenius 2006) that affect the sonic response of an instrument in a high dimensional space. Axel Mulder (2000) classifies it as an “alternate” controller since it does not resemble any traditional musical controller, nor does it restrict the performer’s movement in any way; in fact, it increases the control bandwidth of a performer.
This design choice is due to the fact that we extract musical control information from the performer’s voice, consisting in an indirect gestural data acquisition (Wanderley and Depalle 2004) that can be affected by noise and errors. This is a common drawback in most voice-driven systems, which are usually used for non mission-critical tasks. The adoption of complex statistical models may minimize errors but introduces latencies, which are not acceptable for musical interfaces. We identify as critical musical controls those that require precision in the discrete tempo-frequency grid, such as note generation. An erroneous note may affect melody, harmony or rhythm, and the listener easily identifies it. Therefore, we consider it best — but not mandatory — to map note triggering using traditional touch-based interfaces, whereas the voice can be exploited to modulate multiple real-valued parameters that affect, for instance, the timbral characteristics of a DMI, which are in general less critical, since their domain is continuous.
The use of the vocal timbre as the gestural input modality introduces high variabilities in the system. At the same time, adapting the mapping to the parameters-to-sound characteristic of a specific instrument is not trivial. Therefore, to ease the system setup procedure we use automatic and generative strategies (Hunt et al. 2000) that make extensive use of machine learning and dimensionality reduction techniques to compute the mapping (Caramiaux and Tanaka 2013). In the VCI4DMI we employ mostly unsupervised techniques to further minimize the amount of data that the user has to provide to the learning algorithms. This implies that the user, in turn, has to learn the outcome of the automatic mapping process, which can be further adjusted during performance.
System Overview
The VCI4DMI allows the user to simultaneously control a set of real-valued parameters in a specific DMI with a particular “vocal gesture” and it automatically adapts the mapping by a prior learning stage in which it analyses and processes the specific characteristics voice and instrument. The interface is based on a dual-layer mapping strategy: one layer is dedicated to the voice and the other to the instrument; both are then adapted to the information obtained during the training phase. The analysis and learning processes for voice and instrument are kept separated as well. This approach allows the reusability of the same voice map with different instruments and vice versa, a further simplification of the system setup.
The VCI4DMI aims to shift the cognition of control from synthesis parameters directly to the perceptual sonic characteristics of the sound. This is a key aspect here because the voice as well, which is the gestural input of the interface, is produced with cognitive attention on the sound timbre, ignoring the dynamics in the vocal articulations. Therefore such techniques can provide rational and natural musical control while reducing and hiding the DMI control space from the user.
Instrument Analysis
The DMI analysis and mapping approach is based on an extension of the work presented by the authors at ICMC 2012. In this context we consider a DMI any device that generates or processes a sound signal, for example, a sound synthesizer or an audio effects processor, or any combination of these. The relationship between the DMI’s parameters and output sound must be deterministic and we assume that neither the user nor the system have any prior knowledge of the synthesis / processing algorithms. The subset of instrument parameters that will be mapped to the interface must be specified. Therefore an automatic procedure generates all the possible combinations of DMI parameters and for each one it analyses the output sound computing a vector of perceptual-related sonic descriptors. The DMI analysis and data post-processing stages return a matrix “I” which includes all the unique combinations of the instrument-variable control parameters and represents the DMI control space, and a matrix “D” which contains descriptors of the resulting sound timbre and represents the DMI high-dimensional sonic space. These matrices have different dimensionality but an equal number of entries (or cardinality), and therefore the unique relationship between entries of the two spaces fully characterizes the instrument behaviour, subject to the variation of the selected control parameters. In order to analyse the output of sound processors, the system provides them with a test signal that is either noise or impulses. The different mode of analysis and options are described below. We reduce the sonic representation of the instrument “D” to a lower dimensional space “D*”, typically to two or three dimensions in the VCI4DMI context, using non-linear dimensionality reduction techniques such as ISOMAP (Tenenbaum, de Silva and Langford 2000).
The DMI mapping is based on the inverse relationship “D*” to “I” and the instrument parameters are retrieved browsing or navigating the reduced sonic space and transforming the coordinates in “D*” into a parameters set. This is similar to the intermediate perceptual layer approach presented by Daniel Arfib et al. (2002). Regardless of the nature of gestural control used to browse or navigate the reduced sonic space “D*”, its arbitrary shape and the likely non-uniform distribution determine a nonlinear response between controller and sound. In particular, in sub-regions of “D*” with high density, gesture nuances can determine wide sound variations, while the interface would result unresponsive when browsing or navigating into low-density or sub-regions of “D*”. To address this issue we implement the mapping between DMI sonic space and vocal gesture within an uniformly distributed hypercube, assuming that voice and sonic space have been previously reduced to the same dimensionality. We find the transformation that maps the samples in “D*” into a uniform hypercube maintaining the neighbourhood relations between the space entries. This transformation is achieved in two steps: first we apply the rank transformation method, then we use an algorithm based on the Delaunay triangulation that iteratively relocates the entries associated with the nodes of a truss structure (Persson and Strang 2004). Our method is similar to that proposed in 2011 by Ianis Lallemand and Diemo Schwarz in 2011, but we introduce minor modifications to the algorithm to avoid neighbourhood errors at the borders. Finally, we perform a regression using a neural network to learn the inverse of this non-linear transformation, which is then used in the runtime mapping. Since the parameter-to-sound relationship may not be bijective, discontinuities may appear in the DMI parameters generation flow. To reduce this implicit shortcoming we reduce the search in “D*” to a subset of entries that, in the corresponding positions in the space “I”, are neighbours of the DMI parameters vector at the previous iteration. The neighbourhood threshold distance can be user-defined and it affects the response of the system.
Voice Analysis
On the other end of the system, the VCI4DMI handles the variabilities in vocal characteristics and gestures that are inevitably encountered between performers, and also manages the voice capturing hardware. The interface is designed to drive the instrument with unchanged parameters if the performer’s voice timbre doesn’t vary over time (“vocal posture”), while it allows the exploration of the instrument’s sonic space when the voice changes over time (“vocal gesture”). The temporal unfolding of the gesture is not considered here because it would provide only a mono-dimensional control. Therefore, our approach discards the temporal information and considers only the multi-dimensional spatial unfolding of the gesture. This provides a mean to explore the DMI’s sonic space. The system learns from a set of user-provided vocal postures and several instances of identical vocal gesture. We compute a large set of heterogeneous low-level features including Linear Prediction Coding (LPC) coefficients, Mel-Frequency Cepstral Coefficients (MFCC) and Perceptual Linear Prediction (PLP) coefficients (Hermansky 1990). We search for the optimal features computation configuration across about 400 different cases, presenting different window size, window overlap, sampling rate and LPC-MFCC-PLP orders by discarding features that are noisy over the postures, and using the robust ones to compute measure quality ratings related to gesture accentuation and posture stability (Fasciani 2012). The computation configuration that maximizes the overall quality rating is selected and programmed to utilize the vocal gestures provided by the user to compute the high-dimensional gestural input space “V” using only those features marked as robust in the previous stage.
Then we implement a gestural controller (GC) [Rovan et al. 1997] from this space using the self-organizing gesture (SOG) approach described by the authors in a previous article (Fasciani and Wyse 2013). In this method we use output lattice of Teuvo Kohonen’s (1982) self-organizing map as a GC. The network is trained using a variation of the standard algorithm that finds the gestural extrema in the training data and pull the lattice vertices towards these during the weights update iterations.
This also guarantees the preservation of neighbourhood relations and topology between the the input and output spaces that, in this context, are the vocal gesture spatial unfolding (or just space) and the intermediate mapping space determined by the GC output. This method ensures continuity of the GC output signals. Moreover, the data in “V” is pre-processed using clustering, outlier detection and dimensionality reduction techniques. In particular, we use either ISOMAP or a multiclass LDA (Rao 1948) to generate “V*”. The SOG technique compresses and expands the dynamics in “V”, remapping them into a lower dimensional uniform hypercube with the same dimensionality of the one embedded in “V”, that for voice data is typically two or three.
Mapping
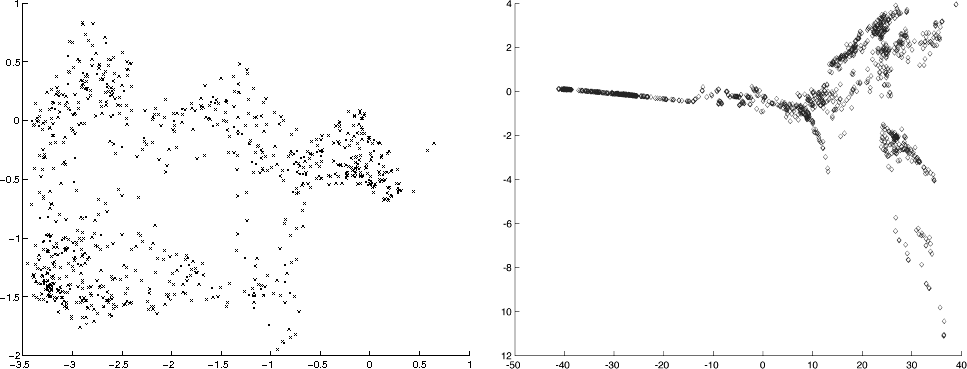
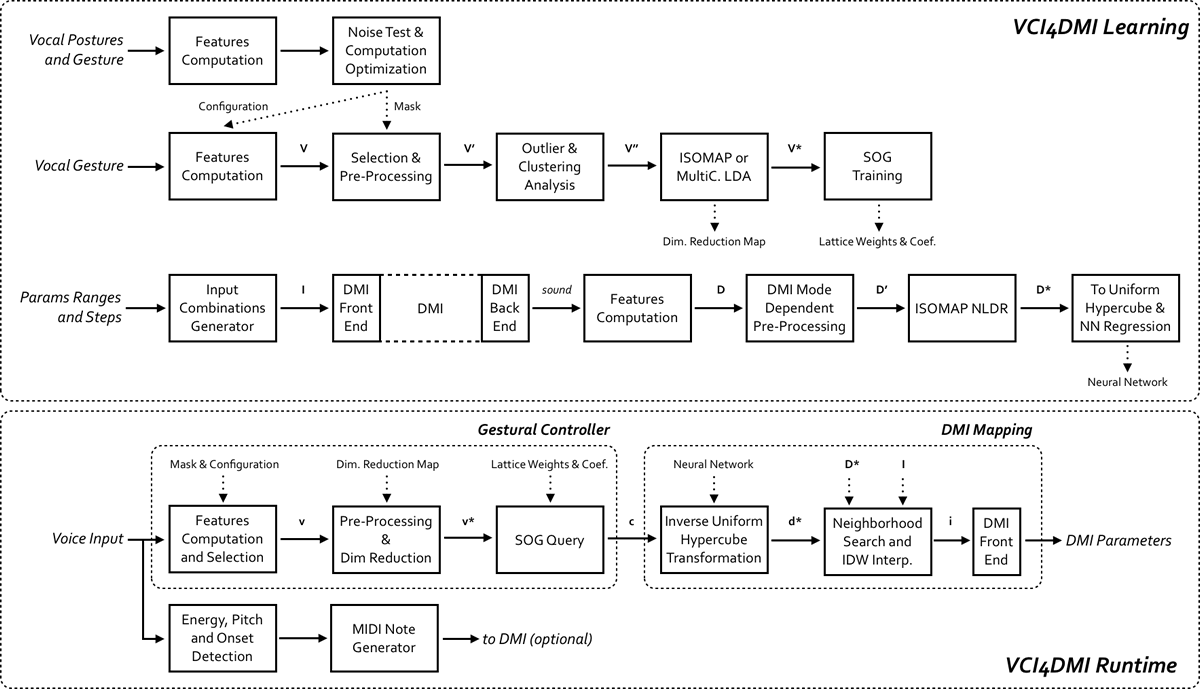
The two learning stages described above map the vocal gesture and the DMI’s sonic space to equal dimension and uniformly distributed hypercubes. Hence the connection between the two layers of the VCI4DMI is simply a linear, one-to-one mapping. This is possible despite the different dimensionality, shape, distribution and number of elements in “D” and “V”. Indirect distance weighting is used in both spaces as an interpolation technique to cope with regions where the density of samples is low. In the runtime interface the hypercube mapping is direct in the voice-related layer, while it is inverse in the DMI-related section. In Figure 1 an example of the two spaces after a reduction to two dimensions is shown.
The differences between the spaces are evident and not predictable, therefore generative mapping techniques offer an effective solution in this context. The mapping tuning options and the DMI parameters retrieval preferences are described in the next section. Figure 2 presents simplified schemes of the offline learning phase and runtime part of the VCI4DMI. In the bottom section, the vector “c”, exchanged between the two layers, represents the GC output within the uniformly distributed hypercube.
User Perspective
A functional prototype of the VCI4DMI is implemented concurrently in Max/MSP using the FTM extensions (Schnell et al. 2005) and MATLAB. We developed a set of Max for Live devices to easily interface DMIs hosted in Ableton Live. In this section we describe the procedure that the user has to follow to train and use the system. Moreover, we report all the available choices in the learning phase and in the runtime part. Most of these are exposed in the Max/MSP Graphical User Interface (GUI) and eventually propagated to MATLAB using the Open Sound Control protocol.
Learning Phase
At first, the user has to identify the DMI parameters that will be controlled by the system (up to eight in the prototype but theoretically unlimited). For each one, the user specifies range and analysis resolution. These directly affect the number of entries in “I”, in “D”, and in turn the overall analysis and learning time. From our experience, an excessive number of unique parameters combinations do not bring usability improvement to the system, since an interpolation method is in place. For synthesizer, the analysis features available are the energy of the Bark bands, the MFC coefficients or spectral moments. The user must also select one of the following analysis modes: sustain phase averaging, attack-decay-release envelopes or sustain phase dynamics. For effects it is possible to run the analysis in the frequency or in the time domain. In the first case, we use noise (white, pink or brown) to excite the DMI and then it can be analysed with the same synthesizers available modalities. For the time domain option, the sound processor is excited with an impulse and the response is captured. The impulse response can be down-sampled and used directly as a high-dimensional feature vector or it can be processed to compute a more compact feature vector composed by the total energy, the slope, the RT60, the number of peaks, the maximum amplitude time and temporal position. For both DMI categories, synthesizers and processors, the GUI allows the user to fine tune low-level analysis parameters such as window size and overlap, number of bands, MIDI note and velocity, analysis timings, number of feature vectors per state, impulse response duration and individual feature mask.
The SOG GC can be trained using any vocal gesture that comprises any sequence of voiced and unvoiced sounds. As mentioned before, the temporal unfolding of the gesture is not considered by the system, but the focus is on the spatial unfolding of the low-level vocal features. The user must provide several instances of the same vocal gesture and the vocal postures. A basic example of gesture is the gliding between the vowels [i] and [u], and the two related postures would be exactly the vocal sounds [i] and [u]. Gestures and postures can be captured “on the fly” or provided to the training script as audio files. In the latter case, all the feature computation parameters (sample rate, window size, window step, pre-emphasis, order of LPC, MFCC and PLP) are set automatically to optimal values found by an iterative algorithm, instead of leaving them to default values or user-defined values.
Runtime Interface
The mapping layers generated in the learning stages are saved into separate memory structures and dumped to binary files, so that they can be reutilized in different interface implementations. When starting the runtime VCI4DMI, the user has to load a pair of maps — one for the voice and another for the instrument. Since we used only unsupervised techniques in the learning process, at first the user should learn and get familiar with the mapping that the system has generated. However the GUI exposes a large set of parameters and options that advanced users can use to tune or change the default VCI4DMI response. These, visible in the GUI detail in Figure 3, can be changed while the system is running. The response can be modified between these two theoretical extremes: specific vocal timbres mapped to specific DMI’s sounds, or vocal timbre variations to browse the DMI sonic space in different directions. The VCI4DMI stores all the user preferences in the map file so that it is not necessary to reconfigure the map again after a recall or system restart.
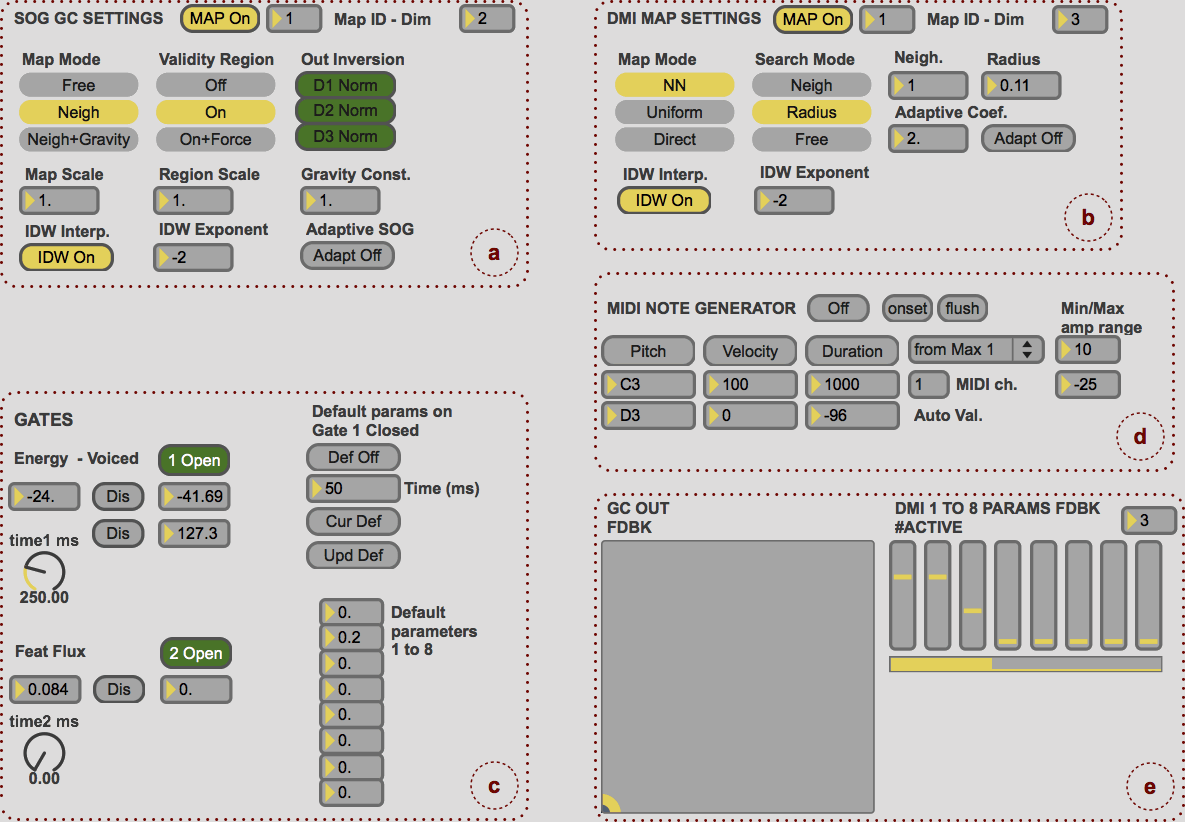
Through the SOG-based GC GUI (Fig. 3a), the user can choose to restrict the movement within the lattice nodes that are in the “Moore” neighbourhood of the output node at the previous iteration. The search metric can be the Euclidean or the gravitational attraction, using a mass value assigned to each output node that was computed during the learning stage, which is directly related to the local training data density. The user can also set how voice vectors outside the validity region are handled: they can be considered, ignored or projected to the boundary of the region. Scaling coefficient can be applied to the lattice and to the validity region, while the mapping of the single GC output dimensions can be inverted. An option to adapt the map during runtime is available as well; it simply computes and applies an offset to every dimension of the weights of the output lattice.
For the DMI mapping section (Fig. 3b), the user can select to bypass the neural network and map the GC output either to the original “D*” or to the “D*” rearranged into the uniformly distributed hypercube. This is useful when the neural network regression performance is poor — such feedback is among those provided to the user during the learning phase. The following search step can be across the entire sonic space, restricted to the first or second “Moore” neighbourhood level, within a user-defined radius or within an adaptive radius dynamically related to the instantaneous voice timbre variation. In all these cases, the neighbours or the points within the radius are measured in the parameter space “I” and brought back to “D*”. The indirect distance weighting interpolation for the SOG GC and for the DMI mapping can be disabled and the interpolation exponent modified. Moreover, both layers can be bypassed, allowing the incoming data to pass through.
There are three gates available to temporary enable and disable the interface (Fig. 3c), thereby interrupting the flow of input gestural data. These are based on energy, low-level features vector distance and voiced / unvoiced detection. Each one has an independent threshold value and opening time. Further, it is possible to define a default DMI parameters configuration to which the system will force the instrument when the gates are closed. The user can also define the transition time to the default parameters. The VCI4DMI can optionally generate MIDI notes to trigger sound generators. Energy, pitch and onset detected are mapped one-to-one to their MIDI equivalents. The pitch, velocity and duration can be manually defined or individually set to automatic mode so that they are derived from the vocal input. The related GUI section is seen in Figure 3d.
There are four real-time visual feedback provided to the user: position of the GC output in the hypercube, DMI parameters, position and transitions in the SOG lattice with validity region, and position in sonic space with active neighbourhood highlighted. The first two are visible to the user in the GUI (Fig. 3c), while the others are generated in MATLAB and superimposed to the two static plots in Figure 1. The visual feedback plays a key role in getting familiar with and tuning the automatically generated mapping. The system can also be tuned to respond more smoothly or sharply by changing the voice signal feature computation window overlap, or the feature first-order IIR low-pass filter. In the current implementation there are three partially optimized tasks running in parallel. In the majority of the real cases we had experimented with, the system was able to generate a new DMI parameter vector up to every 4 ms. The parameter output is further linearly interpolated every 1 ms. The highest impact on the computational load is given by the number of elements in “D” and “I”, representing the unique combination of DMI parameters, followed by dimensionality and number of output nodes of the SOG GC. In the worst-case scenario with 60,000 combinations of DMI parameters, three-dimensional GC with 729 output nodes, the system generates a new output parameter vector every 8 ms. These performances were obtained on a quad core 2.4 GHz Intel Core i7 with 6 MB of cache and a bus speed of 1.3 GHz.
“One at a Time by Voice” System Setup

The version of VCI4DMI used in a recent performance at the Sound and Interactivity Symposium (Fig. 4) was specifically developed with additional features to fit the needs of this scenario. The voice is the only gestural input used to interact with the DMIs, therefore rapid recall of mapping presets, seamless interaction with the DMI-hosting Digital Audio Workstation (DAW), off-screen visual feedback and minimal hand interaction are essential. This specific version loads a bank of voice maps and a bank of instrument maps. Individual elements of the two banks can be paired and saved into a specific preset, which can be recalled with the press of a single button on an external interface or on a remote control. Each preset also stores information about DAW interaction, such as instrument track, input mode (parameters and/or MIDI), record mode and quantization. System visual feedback are encoded and routed to a 9-by-9 LED matrix. To load a new pair of maps the system temporary disables the interface for as little as 150 ms.
The pool of instruments and effects loaded in Ableton Live for this live performance was selected to demonstrate the wide range of sonic interaction capabilities offered by the interface. The pool consists of four different virtual analogue synthesizers, two FM synthesizers, a granular synthesizer, a sampler loaded with four percussive samples, two low-pass filters, a reverberator, a simple delay and a tape delay. Some of the controller parameters were macros provided by the designer of the instrument preset, which consists of a one-to-many mapping. While the DAW loops on four bars, the performer builds up an improvised composition recording on each instrument’s track the MIDI and instrument parameters generated by the VCI4DMI. Only one instrument at a time is controlled directly by the performer. However, for each DMI the performer can control as many as eight real-valued parameters simultaneously and optionally trigger MIDI notes. The track recording and the MIDI generation are enabled separately so that the performer-instrument interaction can be limited to just parameters modulation in specific cases.
Conclusions
We presented the VCI4DMI system 2[2. Demo and performance videos, plus additional material related to the VCI4DMI is available on Stefano Fasciani’s website.]based on a novel mapping method that generates instrument parameters from the vocal input. The user system setup effort was minimized due to the adoption of automatic procedures and unsupervised machine learning techniques. A user evaluation, in which we involved ten experienced electronic musicians, showed how new users were able to train the system, use the basic functionality of this musical controller and perform with a pool of provided instruments in a matter of minutes. Moreover, a preliminary analysis of the interviews with the users involved in the study confirmed our hypothesis on interface limitations and our vision of the use of the VCI4DMI as an extension to modulate real-valued instrument parameters. However the performance discussed here is in contradiction with this statement since the VCI4DMI was the sole interface used in the performance, and was also used to control critical musical tasks. This choice was meant to emphasize the control potential offered by the system and to ease the audience understanding of the mapping. Another aim of the performance was to show that the performer’s hands are essentially free, except during those short intervals in which the performer pushed a button to switch preset. Our experiences have shown that the simultaneous use of a traditional interface and the VCI4DMI is possible, and that such a setup can lead to more complex and expansive musical control for the performer.
The unsupervised learning advantage of minimizing the amount of training data is balanced by the necessity of the user to get familiar with the mapping outcome, and here the visual feedback play an essential role. These are useful also during performances to monitor the system status. The current implementation presents basic visual feedback, complex to understand in the three-dimensional cases. Other limitations of the system are the slowness of the learning phase, which can be deeply optimized, and the absence of a proper noise rejection technique. However a hyper-cardioid microphone and the timed gate on the input level clear the chances of spurious response due to external noise, such as the proximity of loudspeakers. Future works include the improvement of the visual feedback, simplification of the advanced user GUI controls, and the release of the open source code that implements the VCI4DMI. Moreover a dedicated hardware has been developed to free the performer from a dependency on the laptop screen, for the runtime visualizations, and on a generic MIDI controller, for preset switching. It consists of a micro-controller driving a head-worn 1.8-inch TFT LCD and a rotary encoder plus four push buttons placed on the microphone battery pack.
Bibliography
Arfib, Daniel, Jean-Michel Couturier, Loïc Kessous and Vincent Verfaille. “Strategies of Mapping between Gesture Data and Synthesis Model Parameters Using Perceptual Spaces.” Organised Sound 7/2 (August 2002) “Mapping in Computer Music,” pp. 127–144.
Arfib, Daniel and Loïc Kessous. “Gestural Control of Sound Synthesis and Processing Algorithms.” In Gesture and Sign Languages in Human-Computer Interaction. GW01 — International Gesture Workshop, pp. 285–295. London: Springer-Verlag, 2002.
Caramiaux, Baptiste and Atau Tanaka. “Machine Learning of Musical Gestures.” NIME 2013. Proceedings of the 13th International Conference on New Interfaces for Musical Expression (KAIST — Korea Advanced Institute of Science and Technology, Daejeon and Seoul, South Korea, 27–30 May 2013).
Cook, Perry R. 2009. “Re-Designing Principles for Computer Music Controllers: A Case Study of SqueezeVox Maggie.” NIME 2009. Proceedings of the 9th International Conference on New Instruments for Musical Expression (Pittsburgh PA, USA: Carnegie Mellon School of Music, 4–6 June 2009). http://www.nime.org/2009
Dahlstedt, Palle. “Creating and Exploring Huge Parameter Spaces: Interactive evolution as a tool for sound generation.” ICMC 2001. Proceedings of the International Computer Music Conference (Havana, Cuba, 2001), pp. 235–242.
Fasciani, Stefano. “Voice Features For Control: A Vocalist-dependent method for noise measurement and independent signals computation.” DAFx-12. Proceedings of the 15th International Conference on Digital Audio Effects (York, UK: University of York, 17–21 September 2012). http://dafx12.york.ac.uk
_____. “Voice-Controlled Interface for Digital Musical Instruments.” Unpublished PhD thesis. Singapore: National University of Singapore, 2014.
Fasciani, Stefano and Lonce Wyse. “A Voice Interface for Sound Generators: Adaptive and Automatic Mapping of Gestures to Sound.” NIME 2012. Proceedings of the 12th International Conference on New Interfaces for Musical Expression (Ann Arbor MI, USA: University of Michigan at Ann Arbor, 21–23 May 2012). http://www.eecs.umich.edu/nime2012
_____. “Adapting General Purpose Interfaces to Synthesis Engines Using Unsupervised Dimensionality Reduction Techniques and Inverse Mapping from Features to Parameters.” ICMC 2012: “Non-Cochlear Sound”. Proceedings of the 2012 International Computer Music Conference (Ljubljana, Slovenia: IRZU — Institute for Sonic Arts Research, 9–15 September 2012).
_____. “A Self-Organizing Gesture Map for a Voice-Controlled Instrument Interface.” NIME 2013. Proceedings of the 13th International Conference on New Interfaces for Musical Expression (KAIST — Korea Advanced Institute of Science and Technology, Daejeon and Seoul, South Korea, 27–30 May 2013).
Hermansky, Hynek. “Perceptual Linear Predictive (PLP) Analysis of Speech.” The Journal of the Acoustical Society of America 87/4 (April 1990), pp. 1738–1752.
Hunt, Andy, Marcelo M. Wanderley and Ross Kirk. “Towards a Model for Instrumental Mapping in Expert Musical Interaction.” ICMC 2000. Proceedings of the International Computer Music Conference (Berlin, Germany, 2000), pp. 209–212.
Kohonen, Teuvo. “Self-Organized Formation of Topologically Correct Feature Maps.” Biological Cybernetics 43/1 (January 1982), pp. 59–69.
Kvifte, Tellef and Alexander Refsum Jensenius. “Towards a Coherent Terminology and Model of Instrument Description and Design.” NIME 2006. Proceedings of the 6th International Conference on New Instruments for Musical Expression (Paris: IRCAM—Centre Pompidou, 4–8 June 2006), pp. 220–225.
Lallemand, Ianis and Diemo Schwarz. “Interaction-Optimized Sound Database Representation.” DAFx-11. Proceedings of the 14th International Conference on Digital Audio Effects (Paris, France: IRCAM, 19–23 September 2011). http://dafx11.ircam.fr
Miranda, Eduardo R. and Marcelo M. Wanderley. New Digital Musical Instruments: Control and interaction beyond the keyboard. Computer Music and Digital Audio Series, Vol. 21. Middleton WI: A-R Editions, Inc., 2006.
Mulder, Axel. “Towards a Choice of Gestural Constraints for Instrumental Performers.” In Trends in Gestural Control of Music, pp. 315–335. Edited by Marcelo M. Wanderley and Marc Battier. Paris: IRCAM, 2002.
Paradiso, Joseph A. and Sile O’Modhrain. “Current Trends in Electronic Music Interfaces.” Journal of New Music Research 32/4 (2003), pp. 345–349.
Persson, Per-Olof and Gilbert Strang. “A Simple Mesh Generator in MATLAB.” SIAM Review 46/2 (January 2004), pp. 329–345.
Rao, C. Radhakrishna. “The Utilization of Multiple Measurements in Problems of Biological Classification.” Journal of the Royal Statistical Society — Series B 10/2 (1948), pp. 159–203.
Rovan, Joseph Butch, Marcelo M. Wanderley, Shlomo Dubnov and Philippe Depalle. “Instrumental Gestural Mapping Strategies as Expressivity Determinants in Computer Music Performance.” Proceedings of Kansei: The Technology of Emotions Workshop (Genoa, Italy: AIMI and University of Genoa, 1997).
Tenenbaum, Joshua B, Vin de Silva and John C. Langford. “A Global Geometric Framework for Nonlinear Dimensionality Reduction.” Science 290 (2000): 2319–2323.
Wanderley, Marcelo M. and Philippe Depalle. “Gestural Control of Sound Synthesis.” IEEE 2004. Proceedings of the IEEE International Conference 92/4, pp. 632–644.
Wessel, David and Matthew Wright. “Problems and Prospects for Intimate Musical Control of Computers.” NIME 2001. Proceedings of the 1st International Conference on New Instruments for Musical Expression (Seattle WA, 1–2 April 2001). http://www.nime.org/2001
Social top